
ストリーム処理のフレームワークが備える backpressure という機能がある。
このポストでは Apache Flink の backpressure について調べたことを記載する。
Backpressure の目的
backpressure はストリーム処理システムにおける負荷管理の仕組みの一つ。
一時的な入力データ量の増大に対応する。
インターネットユーザの行動履歴やセンサーデータなどは常に一定量のデータが流れているわけではなく、単位時間あたりのデータ量は常に変動している。
一時的にスパイクしてデータ量が増大するようなことも起こりうる。
複数の operator からなる dataflow graph により構成されるストリーム処理システムにおいては、処理スピードのボトルネックとなる operator が存在する。
一時的に入力データ量が増えてボトルネックの operator の処理速度を上回ってしまった場合に、データの取りこぼしが発生するのを防ぐのが backpressure の目的となる。
Backpressure の仕組み
Buffer-based
ここでは以前のブログでも紹介した、ストリーム処理で必要とされる機能について書かれた Fragkoulis et al. 1 を引用して一般論としての backpressure について述べたい。
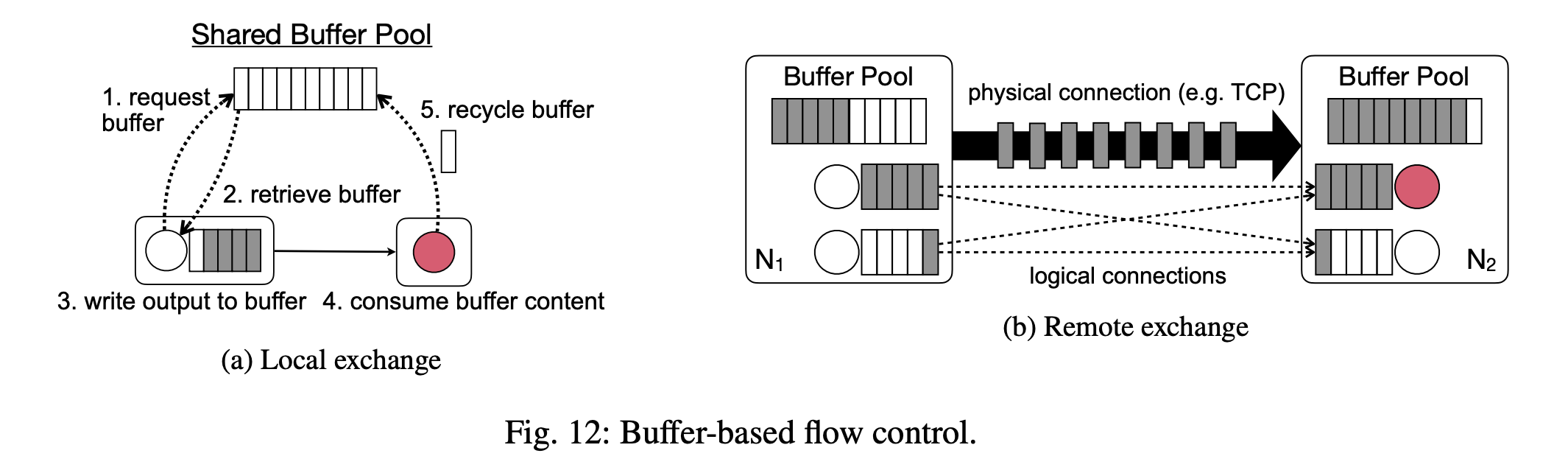
上流/下流の operator をそれぞれ producer, consumer とする。
producer, consumer (それらの subtask と言ってもいいかも) がそれぞれ異なる物理マシンに deploy されているケースが Figure 12b となる。
各 subtask は input と output の buffer を持っており、
- producer は処理結果を output buffer に書き出す
- TCP 等の物理的な接続でデータを送信
- consumer 側の output buffer にデータを格納
- consumer がそれを読み込んで処理する
というような流れになる。
buffer はマシンごとの buffer pool で管理されており、input/output で buffer が必要となった場合はこの buffer pool に buffer が要求される。
ここで赤い丸で示されている subtask の処理速度が入力データの速度よりも遅かったとする。
consumer 側の input buffer の待機列が長くなり、さらにこの状況が続くとやがて buffer pool の buffer を使い果たす。
すると producer 側から新しいデータを送信することができなくなり、producer 側の output buffer を使い始める。
同様に producer 側でも output buffer を追加できなくなると producer は処理を待たざるを得なくなる。
このようにボトルネックとなる operator から上流に向かって buffer が埋まっていくことになる。
これが backpressure だ。
dataflow graph を構成する operator 全体、物理的にはそれらのマシンのメモリにより一時的なデータ量の増加を buffer するという形になる。
Figure 2a は producer と consumer が同じマシンにある場合の例であり、この場合はネットワークを介さずに buffer 上でやりとりができる。
ボトルネックがあれば同様に buffer を使い切り、それが上流に向かって伝播していくことになる。
Credit-based
上記のような buffer-based な流量制御の場合、複数の channel が同じ下流のマシンにデータを送信する場合、同じ TCP socket を使うことになる。
下流のある一部の channel が遅延して backpressure が働くと (data skew) 上流のすべての channel が影響を受けるという問題がある。
これを解決するのが credit-based な流量制御であり、Figure 13 はそれを示したものである。
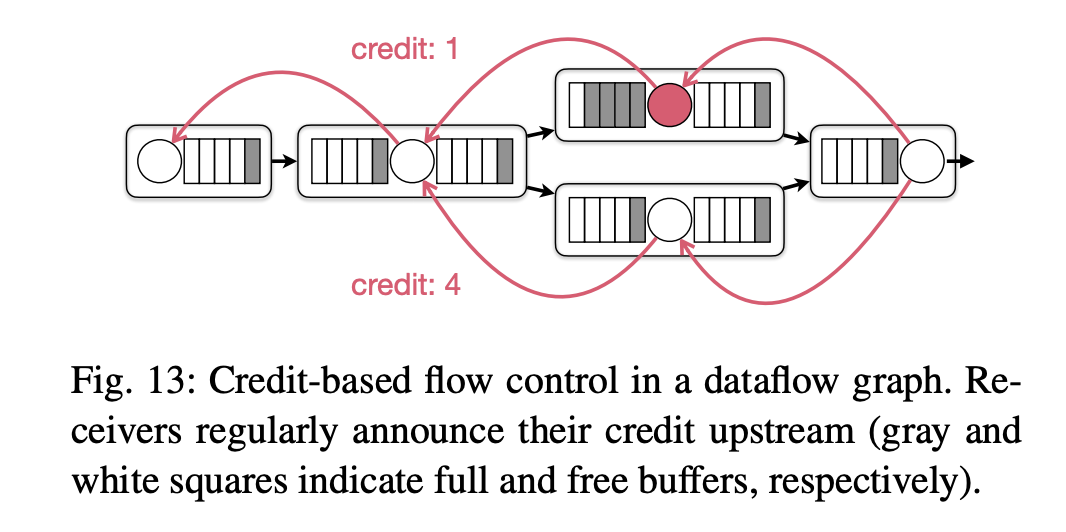
データ送信を試みる前に credit という形で consumer 側から producer 側に buffer 状況を送信する。
ある channel で consumer の buffer がなくなると credit=0 となり、producer 側でその channel に送信できなるなり backpressure が発生する。
一方、並列する他の channel には backpressure はかからず、TCP socket は利用可能となっている。
Flink の Backpressure
残念ながら Flink 公式のドキュメントには backpressure についてあまり詳しく説明されていない。
モニタリングについて書かれているのみである。
backpressure が起こっているかどうかは web UI 上から確認できるとのことだ。
一方で Flink のブログや Alibaba のブログ等では内部的な挙動が詳しく書かれている。
- Analysis of Network Flow Control and Back Pressure: Flink Advanced Tutorials
- A Deep-Dive into Flink’s Network Stack
前述のように buffer-based な仕組みの上に credit-based な挙動が採用されていることがわかる。
ここで Flink の設定の中で backpressure に影響がありそうなものを見ておく。
taskmanager.network.memory.buffers-per-channel
こちらは channel 単位の排他的な buffer の数を指定する。
skew 発生時において、この値が大きすぎると遅延している channel 以外で buffer が遊ぶことになり、逆に小さすぎると遅延していない channel でも処理が滞りやすくなると考えられる。
taskmanager.network.memory.floating-buffers-per-gate
すべての input channel で共有される floating buffer の数。
この部分で skew をある程度吸収しようとするのだろう。
taskmanager.network.memory.max-buffers-per-channel
channel ごとの最大 buffer 数。
最大 buffer 数を制限することにより skew 時に backpressure が起こりやすくなり、結果として checkpoint のアラインメントを速くする効果があるとのこと。
最大 buffer 数の制限がゆるいとボトルネックの operator で長い待ち行列を待つ必要があり、checkpoint barrier が移動するのに時間がかかってしまうということだろうか。
web.backpressure.cleanup-intervalweb.backpressure.delay-between-samplesweb.backpressure.num-samplesweb.backpressure.refresh-interval
上の4つは web UI によるモニタリング関連の設定値であり、backpressure 関連の挙動に直接影響を与えるものではない。
…と書いてみたものの通常はこれらの値をチューニングすることはあまりないのではという印象。
まとめ
Flink の backpressure がどのように働くかがだいたい概観できた。
そもそもなぜ backpressure を調べたかというと今開発している Flink アプリケーションで checkpoint size が増大し続ける問題があって backpressure の影響を疑っていた。
結局 backpressure は関係なさそうだな…