
このポストについて
DMBOK2 を読み進めていくシリーズ。
今回は第12章「メタデータ管理」について。
仕事でメタデータを扱い始めたので読んでおきたかった。
以降、特に注釈のない引用は DMBOK2 第12章からの引用とする。
メタデータとは
一般的な説明としては「データに関するデータ」とよく言われている。
データに関するデータはすべてメタデータなので、メタデータはとても幅広い内容となっている。
DMBOK2 ではメタデータの説明として図書館の例を挙げている。
そこには数十万の書籍と雑誌があるのに、図書目録がない。図書目録がなければ、読者は特定の本や特定のトピックの検索を開始する方法さえ分からないかもしれない。図書目録は、必要な情報 (図書館が所有する本と資料、保管場所) を提供するだけでなく、利用者が様々な着眼点 (対象分野、著者、タイトル) から資料を見つけることを可能にする。 (中略) メタデータを持たない組織は、図書目録のない図書館のようなものである。
データという資産を管理するためにも、データを利用するためにも、リスクマネジメントのためにもメタデータは必要となる。
メタデータの種類
メタデータはビジネス、テクニカル、オペレーショナルの3つに分類することができる。
ビジネスメタデータ
主にデータの内容と状態に重点を置く。
IT からは独立している。
- dataset, table, column の定義と説明
- 業務ルール、変換ルール、計算方法、導出方法
- データモデル
- etc.
テクニカルメタデータ
技術的詳細やシステムに関する情報。
主に IT に関連している。
- 物理 database の table, column の名称
- column のプロパティ
- アクセス権
- etc.
オペレーショナルメタデータ
データの処理とアクセスの詳細を示す。
運用で得られる情報とも言える。
- バッチプログラムのジョブ実行ログ
- データの抽出とその結果などの履歴
- 運用スケジュールの以上
- etc.
以上、各種のメタデータで例に挙げたのはあくまで一部であり、現実にはもっと多くのメタデータが存在する。
メタデータを管理する意義
図書館の例からもわかるとおり、メタデータなしではデータを管理することはできない。
信頼性が高く管理されたメタデータにより、次のようなことができるようになる。
- データのコンテキストを提供し、それによりデータ品質を測定可能にして信頼性を向上させる
- 業務効率の向上、および古いデータや誤ったデータの利用防止
- データ利用者とエンジニアの間のコミュニケーションの改善
- 法令遵守の支援
- etc.
メタデータの管理が不十分だと次のようなことが起こる。
- 一貫性のないデータ利用と誤った定義によるリスク
- メタデータは複製されて保管されることによる冗長性
- 利用者の信頼性低下
- etc.
メタデータアーキテクチャ
メタデータの内容は幅広いがしたがってその取得元も幅広く、ビジネス用語集、BI ツール、モデリングツール、等々が挙げられる。
これらを何らかの方法で集約し、一箇所のメタデータポータルで閲覧できるようにする必要がある。
つまり「ここに来ればデータについてのことがわかる」という入り口を設けることになる。
そのためのアーキテクチャの構成が4つ挙げられている。
集中型メタデータアーキテクチャ
様々なソースから得られたメタデータを保持する1つの中央のメタデータリポジトリを含む。
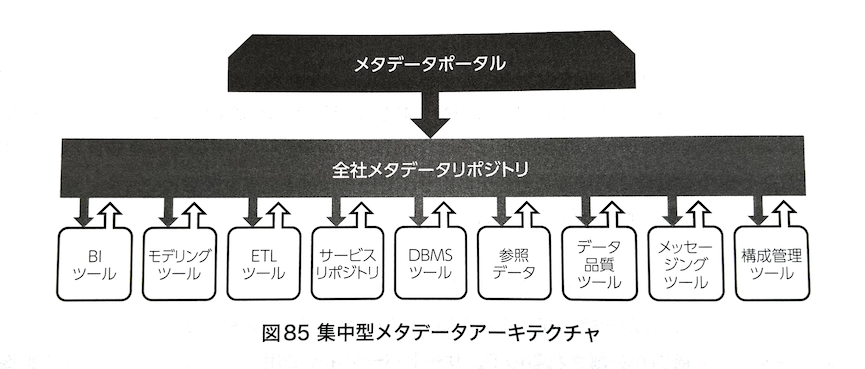
DMBOK2 図85 集中型メタデータアーキテクチャ
分散型メタデータアーキテクチャ
単一のメタデータリポジトリは持たず、メタデータポータルでの検索時に各種ソースのメタデータを直接参照する。
集中型は可用性や検索性など、分散型は鮮度やメンテナンス性などに重きをおいているという違いがある。
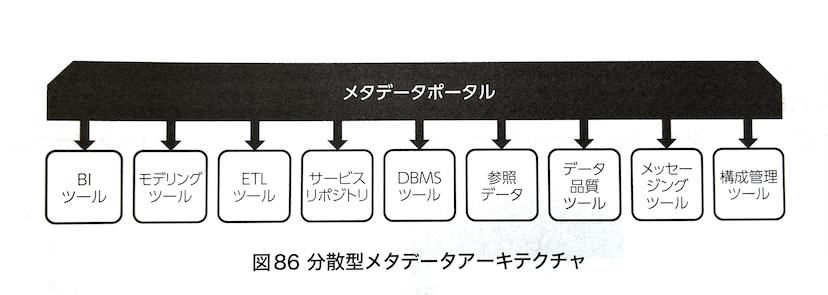
DMBOK2 図86 分散型メタデータアーキテクチャ
ハイブリッド型メタデータアーキテクチャ
集中型と分散型のハイブリッド。
手動で作ったメタデータなどは中央のメタデータリポジトリに起き、それ以外は各種ソースを参照する。
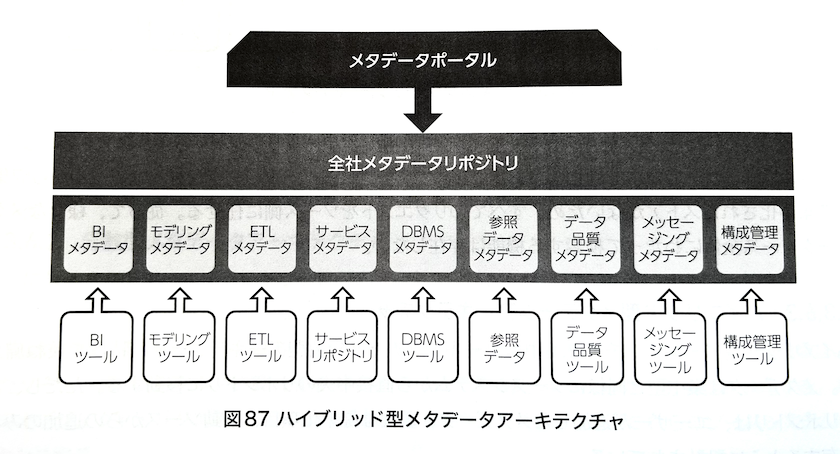
DMBOK2 図87 ハイブリッド型メタデータアーキテクチャ
双方向メタデータアーキテクチャ
メタデータリポジトリまたはソース側のどこでもメタデータの編集を行うことができ、双方向に反映される。
図はなし。
…なんだけど、どうも図のキャプションが各アーキテクチャの説明とずれている気がしてならない。
- 図85 -> 双方向メタデータアーキテクチャ
- 図86 -> 分散型メタデータアーキテクチャ
- 図87 -> 集中型メタデータアーキテクチャ
なのでは?
メタデータ管理の導入
メタデータ管理の活動は次のような流れになる。
- メタデータ戦略の策定
- メタデータ要件の把握
- メタデータアーキテクチャの定義
- メタデータの作成と維持
- メタデータのクエリ、レポート、分析
また
組織へのリスクを最小限に抑え容易に受け入れてもらえるように、管理されたメタデータ環境を段階的に導入することを薦める。
とある。
まずはメタデータリポジトリを実装し、その後必要に応じてインタフェースなどを追加していく。
(とはいえ最近のメタデータツールならリポジトリと UI が一緒になっていたりする)
メタデータを管理しないことによるリスクのリスクアセスメント、メタデータを維持管理していくための組織と文化の変革も必要。
所感
データマネジメントに関心がない人にメタデータの意義を説明するのは難しいと感じる。
このへん上手く話せるようになりたい。
そもそもメタデータって?というところからになるが、図書館の例はわかりやすいので使っていこうと思う。
「信頼性」という言葉がたびたび出てくるがデータを提供するにあたって信頼性はとても重要で、データ資産を利用してもらえるか、つまりデータ資産の価値に大きく影響を与えるとの認識。
信頼性が大事だということを理解してもらうのも意外と難しい。
現在業務で OpenMetadata を使ったメタデータ管理の導入を進めているので、これについても気が向いたら何か書きたい。
私はデータエンジニアなので技術スタックやツールから考えがちだが、実際はメタデータリポジトリに何を入れるかやそれをどうメンテするかが肝だということがわかった。
メタデータの付与や更新は中央のデータチームだけではまかなえず、データプロバイダーである組織内の各チームの協力は必須。
付与だけでなくメンテナンスも含めて組織として体制をつくる必要があり、ガバナンスの力が効いてくるのだろうなと。