
はじめに
このポストではストリーム処理の survay 論文の話題に対して Apache Flink における例を挙げて紹介する。
論文概要
2020年の論文。
過去30年ぐらいのストリーム処理のフレームワークを調査し、その発展を論じている。
ストリーム処理に特徴的に求められるいくつかの機能性 (functionality) についてその実現方法をいくつか挙げ、比較的古いフレームワークと最近のフレームワークでの対比を行っている。
このポストのスコープ
このポストでは前述のストリーム処理システムに求められる機能性とそれがなぜ必要となるかについて簡単にまとめる。
論文ではそこからさらにその実現方法がいくつか挙げられるが、ここでは個人的に興味がある Apache Flink ではどのように対処しているかを見ていく。
ちなみに論文中では Apache Flink はモダンなフレームワークの1つとしてちょいちょい引き合いに出されている。
ここでは Flink v1.11 をターゲットとする。
以下では論文で挙げられている機能性に沿って記載していく。
Out-of-order Data Management
Out-of-order
ストリーム処理システムにやってくるデータの順序は外的・内的要因により期待される順序になっていないことがある。
外的要因としてよくあるのはネットワークの問題。
データソース (producer) からストリーム処理システムに届くまでのルーティング、負荷など諸々の条件により各レコードごとに転送時間は一定にはならない。
各 operator の処理などストリーム処理システムの内的な要因で順序が乱されることもある。
out-of-order は処理の遅延や正しくない結果の原因となることがある。
out-of-order を管理するためにストリーム処理システムは処理の進捗を検出する必要がある。
“進捗” とはある時間経過でレコードの処理がどれだけ進んだかというもので、レコードの順序を表す属性 A (ex. event time) により定量化される。
ある期間で処理された最古の A を進捗の尺度とみなすことができる。
Apache Flink の場合
Flink ではこの進捗を測るのに watermark という概念が使われている。

Apache Flink Event Time and Watermarks
(図が見にくい場合はページ上部の太陽みたいなマークをクリックして light mode にしてください)
こちらの図でストリーム中の破線で描かれているのが watermark であり、W(11) の wartermark は「timestamp が11以下の event はこの後もう来ないものとみなす」ということを下流の operator に伝えるものである。
watermark は metadata 的なものだが、通常の event と同じようにストリーム中を流れている (これを panctuation という)。
下流の operator が window 処理をしていた場合、W(11) が届いた時点で timestamp が11までのところの window 処理を完結してさらに下流に output することができる。
watermark がいつ・どのような値で発生するかについては Flink application の開発者の実装次第ということになる。
しかし現実的には Writing a Periodic WatermarkGenerator の例にある BoundedOutOfOrdernessGenerator のように、 WatermarkGenerator にやってきた event の event time を元に決めることが多いと思われる。
State Management
ストリーム処理における状態
“状態” とは継続的なストリーム処理の中で内部的な副作用をとらえたもの。
アクティブな window、レコードのかたまり、aggregation の進捗など。
ユーザ定義のものも含まれる。
状態については以下のようなトピックがある。
- Programmability
- プログラミングモデルにおいて状態がどのように定義・管理されるか
- 定義と管理についてそれぞれシステムとユーザの場合がある
- Scalability and Persistency
- 最近のストリーム処理は scalable の時流を汲んでおり、scale out するときに状態をどのように扱うか
- 内外の記憶装置に状態を永続化するという方法がよく取られる
- Consistency
- transaction level の保証について
Apache Flink の場合
ドキュメントの TOP ページ における Flink を表す一文
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
においても “stateful” という言葉が使われているとおり、状態の扱いは Flink の設計思想の中でもかなり重要な部分となっている。
Flink における状態の扱いについてはこちらを参照。
Programmability
Flink では application 開発者が任意の状態を定義することができる。
一方で状態の管理はフレームワーク側でやってくれるので、開発者は checkpoint や restore 等のことは特に配慮する必要はない。
論文中ではこれを “User-Declared System-Managed State” と呼んでおり、最近のストリーム処理システムの傾向となっている。
Scalability
Flink では keyBy() により key-level の状態を持つことができる。
key ごとに並列 task 内での partitioning し、分散することが可能ということである。
Persistency
論文では永続化については scalability と絡めて述べられていたが、Flink のドキュメントでは fault tolerance の文脈で永続化について書かれている。
Flink の fault tolerance の肝は stream replay と checkpointing である。
checkpointing とはストリームと operator の状態の一貫性のあるスナップショットをとることである。

Apache Flink Snapshotting Operator State
この checkpoint を作成する過程で各 operator の状態が state backend へと永続化される。
state backend では RocksDB の key/value store に各 checkpoint, 各 operator の状態が保存される。
(RocksDB 以外にもメモリやファイルシステムなどもある)
Consistency
Flink では checkpoint のインターバルの期間の単位 (epoch という) で一貫性のある状態を永続化する。
上図の barriers がその単位を決めている。
Chandy Lamport algorithm という分散スナップショットの手法がインスパイアされており、unaligned/aligned で各 operator の状態のスナップショットを取るようになっている。
Fault Tolerance & High Availability
Fault Tolerance
ストリーム処理システムにとって fault tolerance は2つの理由から重要である。
- ストリーム処理システムは stateful な計算を終わりのないデータに対して行っている
- fault tolerance がなければ、障害があったときに最初から状態を計算しなおさなければならない
- 一方で、多くの場合過去に処理されたデータは既に失われている
- 最近のストリーム処理システムは分散アーキテクチャを採用している
- 物理マシンの数だけ問題が起こりやすくなる
output commit problem についても考慮する必要がある。
これは出力が公開された位置から状態を復元できることが確かな場合のみ、システムは外界に出力を公開するというもの。
言い換えると、障害からの復旧時などに同じ出力を2回してしまわない、出力を exactly-once にできるかというものである。
High Availability
過去の研究においてストリーム処理システムの可用性は recovery time, performance overhead (throughput & latency), resource utilization により定量化されてきた。
この論文では
A streaming system is available when it can provide output based on the processing of its current input.
を可用性の定義として提案する。
時間ごとの processing time と event time の差により定量化される。
Apache Flink の場合
Fault Tolerance
論文中では Flink は output commit problem については Kafka などの出力先の外部システムの責任とするスタンスだとしている。
Kafka には idempotent producer という機能があり、たぶんこれのことを言っている。
また一方で TwoPhaseCommitSinkFunction の2相コミットによって exectly-once semantics を提供するという方法も示されている。
checkpointing における JobManager を2相コミットの coordinator とみなし、checkpoint barrier が最後の operator に到達するまでをコミット要求相、その後の JobManager からの checkpointing 完了通知をコミット相としている。
コミット相において外部システムへの書き出しの transaction が完了する形となる。
fault tolerance については State Management の項も参照。
High Availability
Flink のプロセスには JobManager と TaskManager があり、前者は cluster に1つだけ動く。
したがって JobManager が SPOF になり、可用性に影響しうる。
high availability (高可用性) を実現するためには JobManager が SPOF となることを避けることができる。
standalone または YARN の cluster として deploy した場合は JobManager が SPOF となることを避けることができる。
以下は standalone の例。
1つの JobManager が leader として動いているが、それが crash すると standby のインスタンスが leader を引き継ぐ。
(論文中では passive replication として紹介)
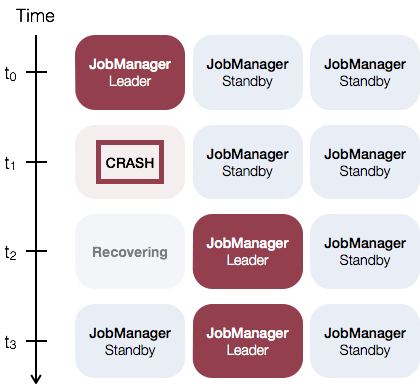
Apache Flink Standalone Cluster High Availability
Load Management, Elasticity & Reconfiguration
Load Management
ストリーム処理システムは、外部のデータソースがデータを送る流速を制御することができない。
入力データの流速がシステムのキャパより大きいことによるパフォーマンス劣化を防ぐための対応が必要となる。
次のような手法がある。
- load shedding
- 多すぎる入力データを落とす方法
- back-pressure
- 入力データを落とせないときに buffering と組み合わせて使う
- dataflow graph 上に速度制限が波及していく
- elasticity
- 分散アーキテクチャと cloud にもとづく方法
- いわゆる scale out
Apache Flink の場合
Flink では back pressure および elasticity の組み合わせとなっている。
back pressure は一時的な入力データの増加に対応する。
各 operator (subtask?) は入出力の buffer を持っており、これにより operator 間の処理速度の違いをある程度吸収できる。
しかし入力データが著しく多くなると
- ボトルネックとなる operator の処理が滞る
- その operator の入力 buffer がいっぱいになる
- (ボトルネックではない) 上流の operator の出力 buffer がいっぱいになる
- 上流の operator の処理が滞る
- (以降繰り返し)
のように、dataflow graph の上流へ上流へと遅延が波及する。
elasticity の面では、JobManager や TaskManager の追加や削除ができるようになっている。
TaskManager の追加や削除においては状態の再配分が行われる。
再配分される状態は key group という単位で partitioning されており、consistent hash 的な方法で各 TaskManager 配下の operator へと配分される。
ちなみに AWS が提供する Flink の managed service である Amazon Kinesis Data Analytics for Apache Flink では CPU 使用率をモニタリングして自動的に scale out が行われるようになっている。
まとめ
バッチ処理ではあまりクリティカルにならないような問題でもストリーム処理では重大な影響を及ぼすことがある。
ストリーム処理に求められる機能性を実現するに当たり、Apache Flink では checkpoint の仕組みが中心的な役割を果たしているということが理解できた。