
業務で AWS Glue Schema Registry を使おうとしたけど、やっぱりやめたというお話。
Glue Schema Registry
What’s Schema Registry?
AWS Glue Schema Registry は2020年に発表された AWS の機能だ。
一方、私が最初に schema registry 的なものを見たのは Confluent の例。
AWS の Glue Schema Registry はこれより後のリリースであり、同等のものの AWS マネージド版といったところだろうか。
schema registry で何ができるかは Confluent のリンク先の図がとてもわかりやすいので参考にしていただきたい。
Glue Schema Registry もだいたい同じで、ストリーム処理のための機能である。
Glue Schema Registry で解決したい課題とその機能
データ基盤上のストリーム処理における schema 管理はバッチ処理のそれとは異なる難しさがある。
これは schema evolution と呼ばれる問題で以前のポストでも述べている。
難しい点として以下のようなことが挙げられる。
- 処理は常に行われており、producer の application 等をしばらく停止させない限りはオンラインで schema 変更をするしかない
- ただしデータ基盤起因で producer を止めることはなるべくしたくない
- オンラインの場合、out of orderness に配慮する必要がある
- deploy 順序、ネットワーク遅延など様々な要因から、新しい schema のレコードが古い schema のレコードより後に届くとはかぎらない
- consumer 側で新旧 schema に対する互換性 (compatibility) に配慮する必要がある
Glue Schema Registry はこの課題に対応する。
ざっと説明すると次のようにして利用される。
- broker (Apache Kafka, Amazon Kinesis Data Stremas, etc.) を挟んで producer と consumer の両方から参照できる場所にバージョン管理された schema 定義を配置する (これが Glue Schema Registry)
- producer からレコードを serialize して送信。レコードには schema のバージョン情報を含む
- consumer はレコードに含まれるバージョン情報と schema registry を参照してレコードの deserialize・解釈を行う
これを実現するために Glue Schema Registry では次のような機能が提供されている。
- schema の登録と互換性ルールにもとづく schema のバージョン管理
- producer, consumer で利用される SerDe ライブラリの提供
- producer 側でのレコード検証、serialize、配信
- consumer 側での deserialize
これによりストリーム処理における producer と consumer の間で schema 変更を運用することが可能になる。
やりたかったこと
…という Glue Schema Registry が自分の業務でも使えるのではないか、そんなふうに考えていた時期が私にもありました。
現在私は B to B to C のビジネスをやっている企業でデータ基盤の開発・運用を行うチームに所属している。
その中で、ある application から発生する JSON 形式のログを near real time でデータ基盤に取り込み、分析したいという案件があった。
以下のようなアーキテクチャを考えた。
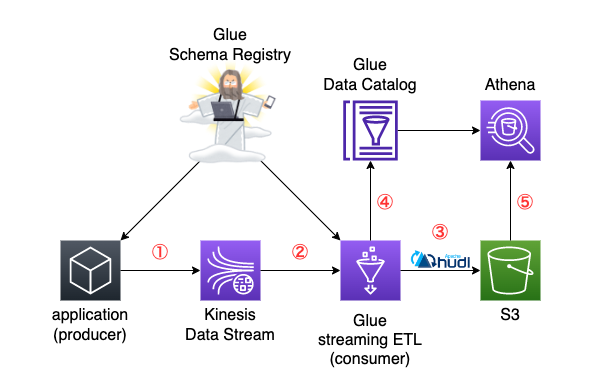
- application 側から SerDe ライブラリを使い、Kinesis Data Streams (KDS) に逐次的にレコードを配信
- Spark Structured Streaming で Glue streaming ETL の job を実装し、KDS を購読してSerDe ライブラリ経由でデータ取得
- Spark Structured Streaming から Apache Hudi の形式 (Merge on Read) で S3 へと保存
- schema の変更がある場合は Glue Data Catalog 上の Hudi table の schema を変更
- Athena でクエリ
(ちなみに Glue Schema Registry のアイコンは AWS では提供されていない)
application はビジネスロジックに近いシステムを担当しているチームの管理であり、それ以降がデータ基盤チームの管理となっている。
near real time 以外でもデータソース側とデータ基盤側の間での schema 管理は以前から課題があり、この Glue Schema Registry を使えばうまくやる前例を作れるのではという期待があった。
4 の schema 変更は自動で行われ、したがって application ログの schema と Hudi table の schema を別で管理・メンテする必要がない。
application 側とデータ基盤側の中間で schema を定義・管理できるのが素晴らしい、そんなふうに考えていた時期が私にもありました。
断念した理由
が、結局は Glue Schema Registry の採用は断念するという結論になった。
次のような理由にもとづく。
- SerDe 導入の壁
- JSON Schema の折り合い
- 互換性の運用の難しさ
以下、それぞれについて述べる。
SerDe 導入の壁
前述のようなアーキテクチャを実現するには、application 側のチームに SerDe ライブラリを導入してもらう必要がある。
SerDe は Java のライブラリとして提供されているため、application 側が Java 系の言語で開発されている必要がある。
ここに大きなハードルがあると感じた。
ちなみに KDS まわりであれば SDK や KPL 経由で使うことも可能である。
今回は application は Scala だったので、頼み込めば今回の案件については導入してもらうこともできたかもしれない。
ただ、うまくいけば今回の案件に限らず横展開したいと考えていたので、それを考えるとかなりハードルが高いという判断となった。
JSON Schema の折り合い
application とデータ基盤の間の schema 管理については data contract という考え方が出てきている。
それについて書かれたブログ記事 7 Lessons From GoCardless’ Implementation of Data Contracts で
For example, most teams didn’t want to use AVRO so we decided to use JSON as the interchange format for the contracts because it’s extensible.
とあるように、Avro 形式を各 application チームに使ってもらうというのはまあまあハードルが高い。
Glue Schema Registry ではレコードの形式として Avro, Protobuf, JSON をサポートしている。
本来はできれば Avro や Protobuf のような、型がしっかりしている形式を使いたいところだが、このようなハードルがあり我々も JSON の仕様を前提に考えていた。
JSON の場合は JSON Schema の仕様に従うことになる。
この JSON Schema、当たり前だが JSON の世界を表現するためのものとなっている。
何が言いたいかというと JSON の世界の型の表現と Hudi table を含めた DB 的な世界の型の表現とが一致しないのだ。
例えば数値表現を見てみると、JSON Schema においては integer, number, Multiples, Range の4つの型が定義されている。
一般的な整数型 short, int, long 等の違いを表現することができない。
Glue Schema Registry に登録された JSON Schema により Hudi の table の schema を自動更新したかったので、これは困ったぞ、となってしまった。
互換性の運用の難しさ
これはちょっと言葉にしにくいのだが、前方/後方互換性まわりの仕様が直感的に理解しにくかった。
どういったときにフィールド追加が許容されるのか、互換性の起点となる checkpoint はどういったときに更新されるのか、etc.
このあたりいろいろ調査すれば理解できると思うのだが、ここまでの課題もあり気持ちが折れてしまった。
また、チームとしてこれを踏まえた schema 更新を運用するのはハードルが高いと感じた。
結局どうしたか
Glue Schema Registry は使わず、では結局どうしたかというと application 側とデータ基盤側の間でシステム的に schema を共有することなく連携する形にした。
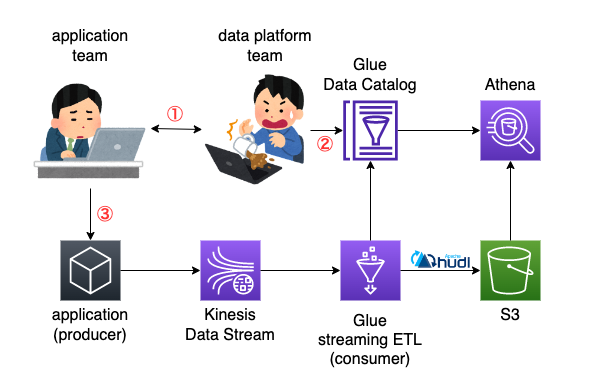
システム的に共有しないので、人が共有してやるしかない。
schema 変更する場合は次のようにチーム間で協調して進める。
- チーム間で認識合わせ
- データ基盤チームによる Glue Data Catalog の schema の変更作業
- consumer に前方互換性があるという前提
- application チームによる application ログの schema の変更作業
このあたりもっとうまくできる方法があるのではと考えている。
とりあえず data contract の発展に期待しておく。
まとめ
ストリーム処理における Glue Schema Registry の思想、考え方は正しいものであると感じる。
ただし、扱いが難しい面があり、今回のユースケースやそれを踏まえた横展開には合わないという判断となった。
チームやシステムをまたいだ schema 管理は簡単ではない。