
このポストについて
このポストは Distributed computing Advent Calendar 2023 の3日目の記事になります。
1日目、2日目に続いて Apache Iceberg について書きますが、このポストでは Iceberg の実用例を書きます。
AWS DMS による CDC の結果を Apache Iceberg 形式にして Amazon Athena でクエリできるようにするという内容になります。
やっていることとしては Perform upserts in a data lake using Amazon Athena and Apache Iceberg | AWS Big Data Blog で紹介されている内容と近いですが、実務としての背景や工夫したところなどを書いていきます。
背景
私の所属する事業会社では日々プロダクトから様々なデータが発生しており、プロダクトの分析やレポーティング、ML など様々な用途で利用されている。
それを支える基盤としてデータ基盤が存在している。
データ基盤ではクエリエンジンとして Amazon Athena を使っている。
ストレージとしては S3 を使用しており、主に分析用として Parquet 形式でデータが置かれる。
ここに業務用の operational な database から日次でデータを取り込んでいる。
データソースは RDS (Aurora MySQL) であり、比較的大きなデータとなっている。
これまではこの RDS -> S3 のデータ取り込みには RDS の S3 snapshot export という機能を利用していた。
この機能では比較的簡単な設定により、バックアップ用のスナップショットの内容を S3 に export することができる。
ちなみに対象 database のスナップショットのサイズは数十 TB ある。
課題
RDS の S3 snapshot export には次のような課題があった。
- 料金が高い 💸
- 料金はデータ送信の量で決まるとのこと
- 具体的な額は伏せるが、思った以上にかかっていた
- export に時間がかかる 🕓
- 数時間程度
- まれに通常より遅延することがあり、1日以上かかることもあった
- export の頻度を高くできない 🐌
- コストも時間もかかるので1日より短くするのは無理
- データソース側で更新されたレコードをデータ基盤上で分析に利用できるまで、最大で1日+数時間のラグがある
- もっと早く分析できるようにしたいという要望もあった
対象 database の特にデータ量の多い table についてレコードの更新タイミングを確認したところ、日によって波はあるが1日の中で更新されているレコードはおおよそ1~4割だった。
スナップショットをまるまる export する場合は更新されていないデータも対象となるため、本来は不要であるはずのデータ移動が発生してしまっている。
ソリューション概要
スナップショット全体のコピーには無駄が多い。
CDC (Change Data Capture) で差分のみ送るようにすればよりデータの移動が少なくなり、上記の問題が解決できると考えた。
CDC とは RDB のデータを外部にレプリケーションする方法の一つで、レコードの追加・更新・削除などのイベントをログとして送信するというやり方。
このようなイベントログがあれば送信先にて table の状態を復元することができる。
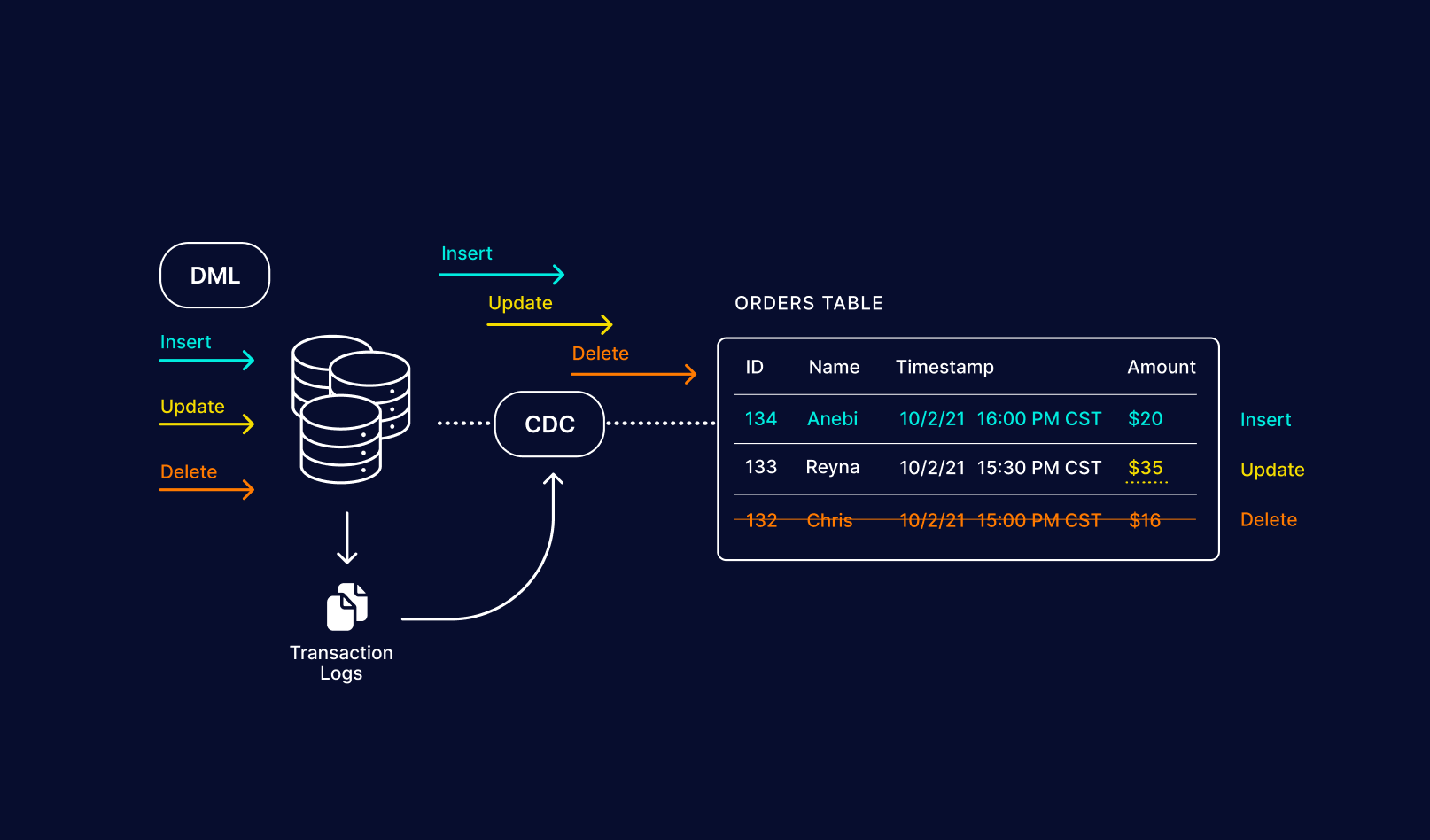
Log-Based Change Data Capture, Change Data Capture (CDC): What it is and How it Works - Striim
CDC については以下も参照。
- Log-Based Change Data Capture in Change Data Capture (CDC): What it is and How it Works - Striim
- Track Data Changes - SQL Server | Microsoft Learn
CDC を実現する方法はいくつかある。
modern data stack 的には Debezium が最も有名だろう。
今回は元々クラウドサービスとして AWS を利用していたため、比較的導入が容易な AWS DMS (Database Migration Service) を使うことにした。
source として RDS、target として S3 を指定して DMS の replication task を動かすことになる。
ちなみに CDC を始める前に現在の table 全体をコピーする full load という処理を実行する必要があるが、このポストでは割愛。
DMS の CDC で S3 へと送信されたイベントログはそのままでは分析に使えない。
元の table と同じ形に組み上げる必要がある。
ここでは Apache Iceberg という table 形式を使ってそれを行うことにした。
Iceberg については当アドベントカレンダーの他のポストや本ブログの Iceberg についてのポストも参考にしてほしい。
Iceberg を採用した理由は以下のとおり。
- Athena でサポートされている table 形式である
- SQL の
merge into文 (後述) により比較的容易にイベントログを元の table の形に復元できる - MOR (Merge on Read、後述) により、コストの低い table 更新を実現できる
Athena および Glue (後述) で使いたいので Iceberg catalog としては Glue Data Catalog を使うことになる。
他に Athena で使えて似たことができる table 形式としては Apache Hudi がある。
しかし以前技術検証したときに Athena のエンジンが Hudi の MOR に対応していなかったため、採用しなかった。
(今はできるかもしれない、未確認)
アーキテクチャは以下のようになる。
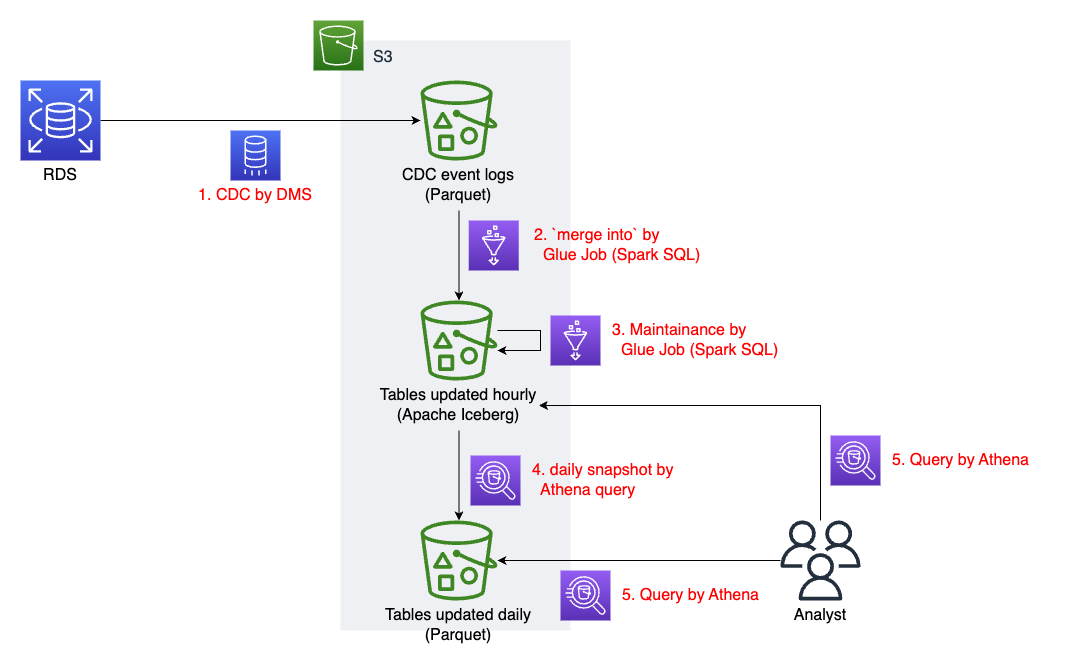
solution architecture
ソリューション詳細
主に Iceberg まわりについて詳しく見ていく。
merge into 文による Iceberg table の更新
アーキテクチャ図の 2. にあたる処理。
DMS の CDC では near real time で S3 にイベントログが出力される。
ただ、今回はデータ基盤については near real time の更新の要件はなかったため、1時間ごとの更新を試みることにした。
ソースである RDS 上の table が 2023-11-11 09:59:59.999999 の時点で次のような状態 (A) だったとする。
| id | name | phone_number |
|---|---|---|
| 1 | Alice | 123-456 |
| 2 | Bob | 456-789 |
これが1時間後には次のようになっていたとする。(B)
| id | name | phone_number |
|---|---|---|
| 1 | Alice | 123-000 |
| 3 | Charlie | 456-789 |
このとき、DMS による1時間分の CDC 結果の出力は例えば次のようになっている。(C)
| Op | timestamp | id | name | phone_number |
|---|---|---|---|---|
| I | 2023-11-11 10:05:00.000000 | 3 | Charlie | 333-333 |
| U | 2023-11-11 10:10:00.000000 | 1 | Alice | 123-000 |
| D | 2023-11-11 10:15:00.000000 | 2 | Bob | 456-789 |
column Op は DMS によって付与される column であり、イベントの種別を表す。
- I: 挿入 (Insert)
- U: 更新 (Update)
- D: 削除 (Delete)
column timestamp も DMS によって付与された column であり、ソース側でその変更が commit された時刻を表す。 (column 名は設定で指定可能)
ソースの table が (A) の状態から (C) に記載されているような変更を経て (B) の状態になった、ということである。
前回までの変更を Iceberg table が追従できているのであれば (A) の状態になっているはずであり、ここで (C) の差分を適用して (B) の状態にする必要がある。
これを自分で実装するとなると結構めんどうだが、幸いに SQL の merge into 文を使って Iceberg table を更新することができる。
この例だと例えば次のような SQL で挿入・更新・削除を一度に適用できる。
merge into
my_catalog.my_database.iceberg_table as iceberg
using (
select
*
from
cdc_table as cdc -- CDC 結果を1時間分だけ読み込んだ DataFrame
)
on
-- この column の一致で同一レコードとみなす (複数指定も可)
iceberg.id = cdc.id
-- 一致する id があり Op=D の場合は削除
when matched and cdc.Op = 'D' then
delete
-- 一致する id があり Op=I or U の場合は更新
when matched and cdc.Op != 'D' then
update set
id = cdc.id,
name = cdc.name,
phone_number = cdc.phone_number
-- 一致する id がなく Op=I or U の場合は挿入
when not matched and cdc.Op != 'D' then
insert(id, name, phone_number)
values(cdc.id, cdc.name, cdc.phone_number)
今回の実装では column 名取得の都合などから Glue Job の Spark SQL でこの SQL を実行するものとした。
ちなみに merge into 文自体は Athena でもサポートしているので、Athena でも実行することができる。
Iceberg table は MOR (Merge on Read) 形式にしており、table 更新時は列指向形式データをすべて書き換えるのではなく差分のみが追加されるようになっている。
このため大きな table であっても比較的低コストでの table 更新が可能となる。
一方で読み取りは COW (Copy on Write) の場合と比べて遅くなるが、基本的には列指向なので分析クエリに対してはそこそこのパフォーマンスとなる。
MOR, COW については以下を参考。
(Dremio さんの Iceberg 解説記事にはいつもお世話になっています!)
daily snapshot の作成
アーキテクチャ図の 4. にあたる処理。
Iceberg table は hourly で更新する一方、Iceberg table から daily でスナップショットとして Parquet 形式に書き出すという処理も追加した。
Iceberg には time travel の機能があり、Iceberg table 自身の中でスナップショットを持つことも可能である。
しかしわざわざ daily スナップショットを外に書き出しているのは、チームとして Iceberg table の運用経験がなく、長期的に安定運用できるかわからなかったため。
例えばもし Iceberg table の metadata がぶっ壊れたら…などと考えると、Iceberg の外にデータを別で持っておきたい気持ちがわかっていただけるのではないだろうか。
元々が daily の更新だったため、最低限 daily のスナップショットが残っていれば少なくとも現在の業務は継続することができる。
分析者視点だと
- 直近1週間 (後述) の鮮度の高いデータの分析 -> hourly 更新の table (Iceberg)
- 長期間におけるデータの分析 -> daily 更新の table (Parquet)
と使い分けてもらうことになる。
後々 Iceberg table が安定運用できることが分かれば Iceberg 1本にしてもいい。
Iceberg table のメンテナンス
前後してアーキテクチャ図の 3. にあたる処理。
ここでは Iceberg table の compaction と古いスナップショットの削除を行う。
これらも daily で実行するものとする。
MOR の場合、更新が何回も行われ差分の世代が多くなってくるとそれらを merge して table としてのデータを読み取る速度が遅くなってくる。
これを解消するためには差分を統合して1つのファイルにまとめる必要があり、これを compaction と言う。
この compaction の処理を追加している。
Iceberg table は内部にスナップショットという概念があり、table の状態を複数バージョン持っている。
これにより time travel query が実行できたり、ACID transction を提供できたりと大きなメリットとなっている。
前述のとおり daily でデータを Parquet として書き出しているので、Iceberg 内で過去の古いスナップショットを持っているとデータの重複になってしまう。
よって定期的に Iceberg 内の古いスナップショットを削除する処理を追加している。
ここでは1週間分残すようにし、それより古いスナップショットは削除するようにした。
compaction、古い snashot の削除はともに Spark SQL から実行することができる。
それぞれ rewrite_data_files(), expire_snapshots() という procedure が対応している。
運用上の工夫
DMS mirgration task の監視
ソースである RDS 側で手動または自動でフェイルオーバーが実行されたり、エンジンバージョンアップが行われたりすると、CDC を継続的に行っている DMS の replication task が Failed で死んでしまうことがある。
したがって replication task の実行状況を監視して通知する仕組みが必須となる。
replication task が失敗した場合は速やかに再度実行することになる。
このあたりの運用はちょっと面倒なので、再実行の自動化を検討している。
遅延チェック
上記とも関係しているが、何らかの理由で CDC の結果が S3 に届くのが遅れることも想定される。
遅れているのに気づかずに「HH 時台の CDC イベントログは全部届いたよね!」とみなして Iceberg table に更新をかけると table が意図しない状態になってしまうかもしれない。
これを防ぐために各時間の merge into 文を実行する前に過去 N 時間分の CDC の出力をチェックして、イベントログが遅れて届いていることがないことを確認するようにしている。
遅れて届いているイベントログがあった場合、procedure rollback_to_snapshot() などで table の状態を rollback することになる。
ちなみにこういった処理の依存関係はおなじみ Airflow (Amazon MWAA) で管理している。
また、合わせて DMS の CloudWatch Mterics の CDCLatencySource や CDCLatencyTarget を見ておくとよい。
それぞれソースと replication instance, replication instance とターゲット間の遅延を表している。
schema evolution
column 追加など、ソース側の table の schema が変更されることは当然起こりうる。
RDS の table を管理しているチームには schema を変更するときは前もって教えてもらえる一応伝えてある。
我々のチームでは通常 Athena というか Glue Data Catalog 上の table の定義は CDK で IaC として管理している。(dbt は未導入)
ただし Iceberg table の schema 変更は metadata として管理される。
当然 CDK というかその中身の CloudFormation では Iceberg の metadata は扱えない。
Iceberg table の schema については IaC に乗せることはできず、DDL で管理することになっている。
merge into 文における単一レコードの複数回操作への配慮
前述の merge into 文のサンプル SQL を見て、例えば同じ id のレコードに対して1時間の中で
- 複数回更新が行われた
- 挿入の後、削除が行われた
など複数回の操作があった場合はどうなるんだ?と思った方はごもっとも。
実際上記のサンプル SQL では複数回の操作を考慮できていない。
なので cdc のレコードをどの順で読み取るかによる、未定義な挙動になると考えられる。
ではどうすればいいかというと、ある id に対して1時間の中で最後に行われた操作だけを見ればよい。
最後の操作が削除であればそのレコードは最終的に存在しないし、最後の操作が挿入または更新であれば存在する。
具体的には using (...) の中の select 文を id ごとに最後の操作だけ見るように書き換えればよい。
ここで「最後」を定義するために column timestamp が必要になってくる。timestamp と window 関数を使ってごにょごにょすると…?
適用の結果 (まだない)
この記事において、適用の結果 AWS コストが◯◯%削減できました!と言えればよかったのだが、まだこの仕組みは運用を始めたばかりであり実績値は出せない。
プロジェクト着手前の試算では結構がっつり減らせる想定ではあった。
前述のとおり処理が多段的になり運用の手間も増えているが、ペイできる程度のコスト削減を見込んでいる。
気が向いたら結果を追記するかもしれない。
まとめ
実際に Apache Iceberg を使っているプロジェクトの実務としての背景や運用について書いてみた。
そんなに新しい内容はないが、ノウハウ的なところはあまり見かけない気がするのでまあ許していただきたい。
今回は Iceberg に注目したので DMS について詳しく書かなかったが、こっちはこっちでいろいろあったりする。
Distributed computing Advent Calendar 2023、明日は Delta Lake についてのお話のようですね。
こちらも興味深いです。
弊チームではこういったお仕事や modern data stack の導入などを一緒にやってくれるデータエンジニアを募集しています。
ご興味のある方は X にて DM ください。
カジュアル面談しましょう。