
データエンジニアリングの領域で少し前から目にするようになった “data contract” という言葉。
なんとなく今の業務で困っている課題の解決になりそうな気がしつつもよくわかっていなかったので調べてみた。
data contract について語られているいくつかのブログ記事などを参考にしている。
Data Contract とは
データの schema というのはナマモノで、いろいろな理由で変更されることがある。
schema を変更する場合、その schema のデータ (table や log) が所属する単一のビジネス機能や application のドメインで行われることになる。
そのドメインの閉じた世界で考える分にはこれで問題ないのだが、DWH や data lake など組織レベルのデータ基盤でデータを流通していた場合はその先のことも考えないといけなくなる。
このようにチームを超える影響というのは、ビジネス機能に責任を持っているチームからは見えにくくなっていることが多い。
上流の application 側で schema を変更したら下流のデータ基盤の ETL 処理がぶっ壊れてしまった、というのはデータ基盤運用あるあるではないだろうか。
というところを解決して平和に過ごせるようにすることが data contract の主なモチベーションだと思われる。
“contract” は日本語で言うところの「契約」。
組織におけるデータ流通において、データの送り手である producer 側と受け手である consumer 側との間で合意した契約を遵守することにより、前述のような問題を避けることができるというのが data contract である。
組織内のデータの見通しがよくなったり、パイプラインを宣言的に開発することができるようになるというメリットもある。
エンジニアにとっては Datafold のブログ記事の例を読むとイメージしやすいかもしれない。
To provide another analogy, data contracts are what API is for the web services. Say we want to get data from Twitter. One way is to scrape it by downloading and parsing the HTML of Twitter’s webpage. This may work, but our scraper will likely break occasionally, if Twitter, for instance, changes a name of a CSS class or HTML structure. There is no contract between Twitter’s web page and our scraper. However, if we access the same data via Twitter’s API, we know exactly the structure of the response we’re going to get. An API has required inputs, predictable outputs, error codes, SLAs (service level agreements – e.g. uptime), and terms of use, and other important properties. Importantly, API is also versioned which helps ensure that changes to the API won’t break end user’s applications, and to take advantage of those changes users would graciously migrate to the new version.
The Best Data Contract is the Pull Request - datafold.com
Twitter から情報を取ることを考えたとき、scraping する場合は UI の変更などで処理が壊れてしまうがちゃんと定義された API を使う場合は処理が壊れない。
この違いは約束事があるかどうかであり、data contract がない場合は約束事がない scraping のようなものだよね、という話。
最初の例ではデータ基盤に流れてくるデータの schema が変わることを示したが consumer は中央集権的なデータ基盤である必要はなく、どちらかというと data mesh のような非中央集権的なコンテキストで話題に上がる方が多い。
また契約の対象となるのは schema だけではなく、次のような様々な情報を含んでよい。
- schema
- 所有者
- 利用者
- セマンティクス
- 更新頻度
- etc.
扱っている情報としては data catalog に近かったりもするが、data catalog はどうなっているかを示しているのに対して data contract はどうなっているべきかを示すという違いがある。
Data Contract の概況
data contract についてはいろいろな人が語っているが、なんとなく現時点でコミュニティにおいてある程度合意がありそうなことをいくつか挙げる。
議論はまだまだこれからという感じなので、これらは時間が経つと変わっていく可能性が高いことに注意。
スタンダードになるようなサービスや製品はまだない
まるっと data contract をやってくれるようなサービスや製品はまだないので、data contract をやりたければある程度自社で作り込んだりルール整備したりする必要がある。
このようなサービスや製品がまだない理由については The Case for Data Contracts - uncomfortablyidiosyncratic.substack.com で議論があったのでご興味のある方はご確認ください。
Schemata という OSS の schema modeling のフレームワークがあるがそんなに広まっていない?
schema metadata についてはわかるけど schema score がどう使われるのかがイメージつかない。
schema は IDL で表現して data contract に含める
data contract の対象の中ではデータの schema は重要視されている。
schema は IDL (Interface Description Language) で記述される。
IDL として代表的なものとして Protocol Buffer と Apache Avro が挙げられる。
schema を記述するための規定の方法が open source で提供されており、これを使ってレコード単位のチェックを行うことができる。
他にも JSON Schema もあるが、DB の世界との間で型の扱いに差があるので個人的にはおすすめできない。
契約の形は様々
契約 (contract) の形は data contract を語る人によっていろいろあってこれが議論になっている模様。
producer 側が主体的な場合もあれば consumer 側が主体的な場合もある。
比較的よく挙げられれているのが pull-request のレビューをもって契約の合意とするという方式。
data contract が規定の形式のドキュメントになっていれば、その追加や変更についての二者間の合意はエンジニアにとって慣れ親しんだ pull-request という形で行うことができる。
The Best Data Contract is the Pull Request - datafold.com の記事が正にこれについて書かれたものとなっている。
後述の実装例でもいくつか紹介する。
Data Contract の実装例
そうは言うてもどないして data contract を実現するんや?ってなりますよね。
というところでその例をいくつか以下に記載してみる。
詳細はリンク先を参照。
例 1
An Engineer’s Guide to Data Contracts - Pt. 1 - dataproducts.substac.com
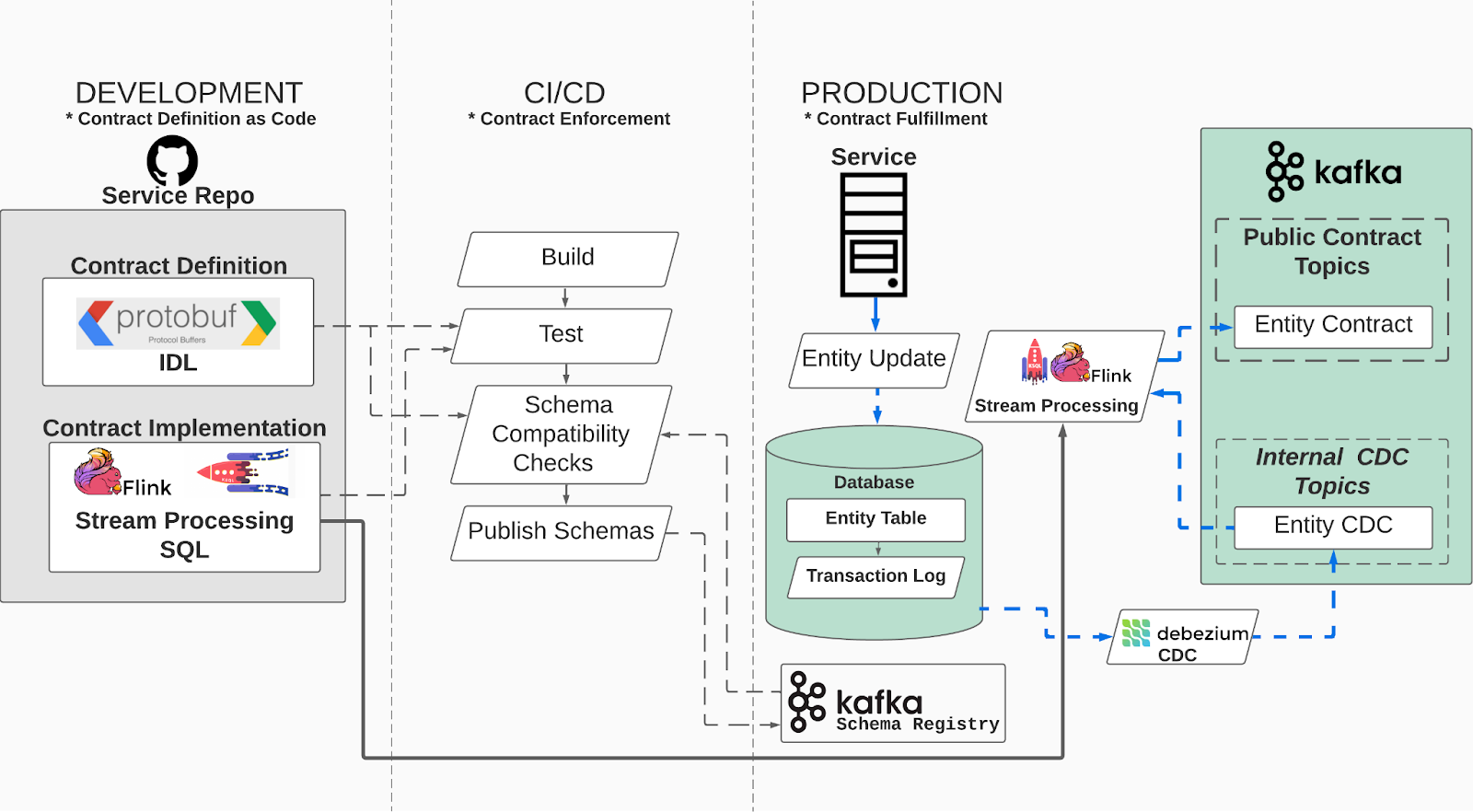
- entity、つまり DB の table の変更を流通させる場合の例
- Pt. 2 の記事では event log の流通について書かれている
- data contract は Protocol Buffers で記載
- data contract は CI/CD でテストや互換性チェックが行われ、Schema Registry に登録される
- production 環境では table の変更が CDC で Kafka の topic に送られている
- Kafka に送られたレコードを KSQL や Flink のフレームワーク + Schema Registry でチェックして新たな topic に
- transactional outbox pattern についても配慮
例 2
Aurimas Griciūnas’ Post - LinkedIn
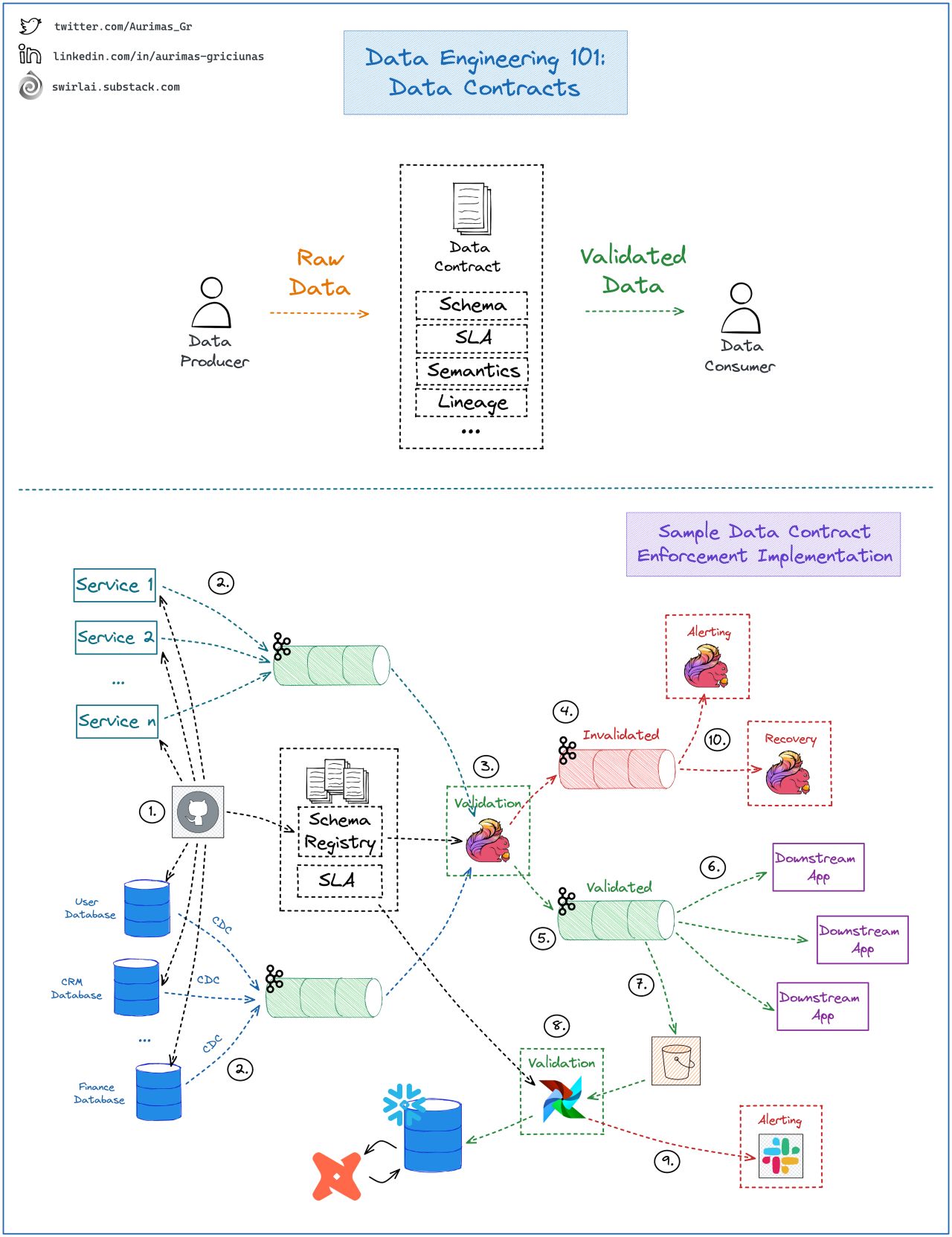
- 別の例だが例 1 に近い
- やはり Kafka や Flink を利用
例 3
Implementing Data Contracts at GoCardless - Medium
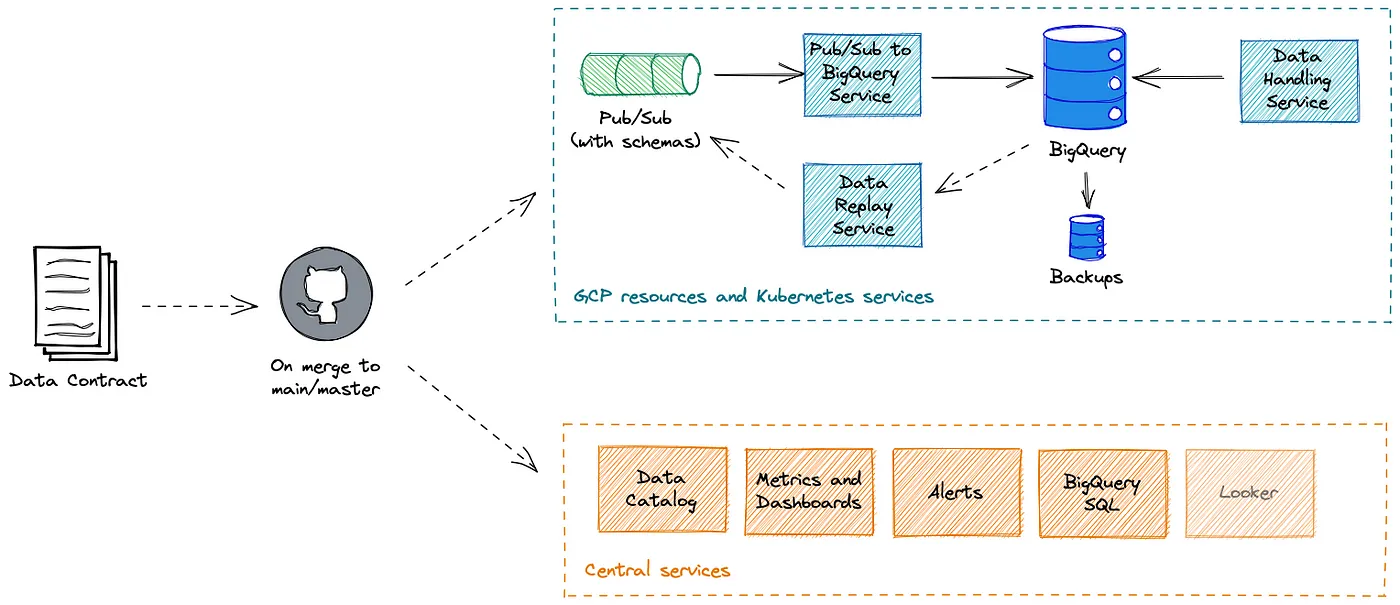
- Pub/Sub や BigQuery に入る前に data contract による validation が行われる
- データ所有者が Jsonnet で定義された data contract を Git で merge すると、必要なリソースやサービスが生成される
- 宣言的でかっこいい
- 契約の主体が producer 側、つまりデータ所有者に寄っている印象
- 所有権を意識させる
例 4
Fine, let’s talk about data contracts - benn.substack.com
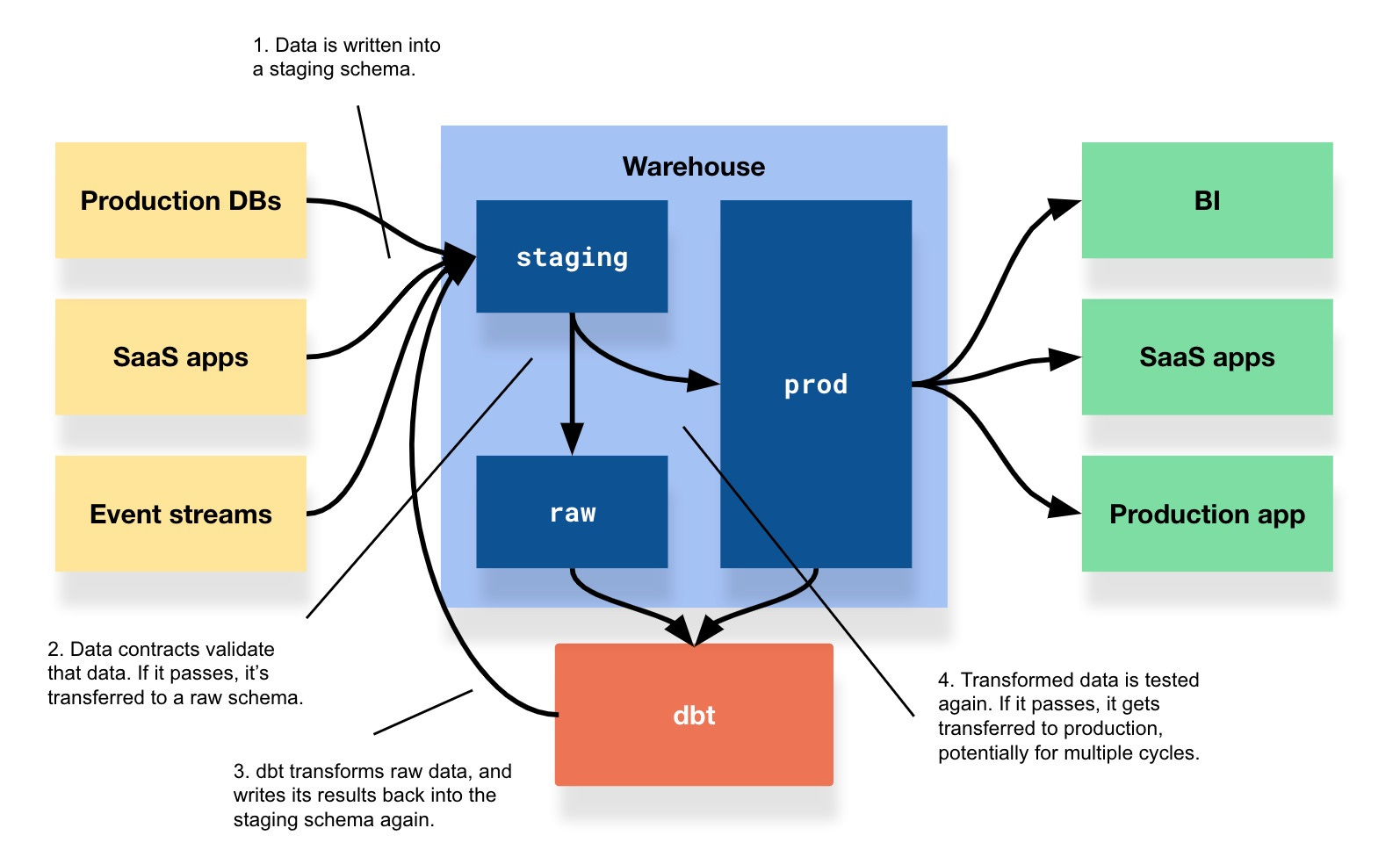
- dbt を使った例
- なのでバッチ処理的なチェック
- 契約の主体が consumer 側、つまりデータ基盤に寄っている印象
- (data contract というよりもデータ品質テストに近い気が)
所感
私がお仕事で運用しているデータ基盤では、最初に挙げたあるあるのような上流のデータの問題で ETL が影響を受けるということが度々あり課題となっていた。
なので data contract という概念には期待がある。
前回の記事 では Glue Schema Registry の導入を諦めた旨を書いたが、data contract という文脈で再度 Glue Schema Registry の採用を検討してみてもいいかもしれない。
一方、国内ではあまり data contract の事例を聞いたことがなく、この辺不思議に思っている。
理由としては
- このような課題が存在しない -> んなわけない
- 課題はあるが認識されていない -> あるかもしれない
- 認識されて data contract 的なことをしているが data contract という言葉が使われていない -> 某社の事例を噂で聞いたことがある
などが考えられる。
国内企業の事例も聞いてみたいところだし、自分のところで事例を出せるといいなとも思っている。
あと CDC とかのリアルタイム処理はもう当たり前になってるんだな。