
前回のポストでは merge on read で Apache Iceberg の table を near real time で更新するということを行った。
このポストではそのメンテナンスについて触れて、かつそれを実行してみる。
merge on read の課題
merge on read で table を更新する場合、copy on write の場合と違い table 全体を洗い替えする必要はなく差分のみを追記することになる。
したがって更新にかかる時間は copy on write よりも短くなる。
一方で merge on read の名のとおり読み出し時に積み重なった差分とベースを merge して最新の snapshot とするため、読み出しの速度は copy on write より遅くなる。
長時間更新され差分がたくさん存在しているとなおさら遅い。
なので
- 更新頻度が低く、参照頻度が高いユースケース -> copy on write
- 更新頻度が高く、参照頻度が低いユースケース -> merge on write
という使い分けがよいとされている。
前回ポストの例では一晩更新を続けた後の merge on read の table に対して簡単な select 文を実行したところ、6分程度かかってしまった。
レコード数はたかだか128件程度であることを考えるとかなり遅いと言える。
このままでは使い物にならない。
しかし更新頻度が高く、参照もよく行われる場合はどうすればいいか?
というところで compaction が必要になってくる。
Compaction
compaction は追加された差分ファイルをベースファイルと merge して新たなベースファイルを作るという処理である。
compaction 後の select クエリは compaction 以前の差分ファイルを読む必要がなくなるため、読み込みが速くなる。
したがって長期的に運用される merge on read の table では定期的に compaction が行われることが望ましい。
Iceberg の公式ドキュメントに compaction の記載があるが、Dremio の記事の方が図もあってわかりやすい。
- Compact data files | Apache Iceberg
- Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files | Dremio
Iceberg で Spark から compaction を行う方法は2つある。
1つは SparkActions.rewriteDataFiles() を使う方法、もう1つは SparkSQL 内で procedure rewrite_data_files を呼び出す方法だ。
今回は主に SparkSQL ベースで実装しているということもあり後者にした。
ちなみに compaction は Iceberg 固有の機能ではなく、Hudi や Delta Lake などでも存在している。
merge on read をサポートする table format においては一般的なトピックだと思われる。
その他のメンテナンス
compaction 以外でも以下2点も対応する。
古い snapshot の削除
長期間 table の更新を続けると snapshot が蓄積していく。
データが大きくなり続けるため、定期的に snapshot を削除していくことが推奨されている。
procedure expire_snapshots により指定の時刻より古い snapshot を削除することができる。
古い metadata file の削除
データ参照の入り口である metadata file も同様に増え続ける。
これも定期的に削除するが、頻繁に更新が行われる table ではこれも削除した方がよい。
metadata file の削除は create table 時に table property として write.metadata.delete-after-commit.enabled および write.metadata.previous-versions-max を指定することで自動で行われる。
このように Iceberg の table 構造は物理的・論理的に多層的になっているので色々なレベルで配慮が必要という印象。
メンテナンスの実装
以上を踏まえて、前回ポスト時の実装に対して変更を追加した。
まず前回作った更新用の app 中の create table を変更。tblproperties として古い metadata file を削除するための設定を追加した。(末尾の2つ)
// Create table
spark
.sql(
"""create table
| my_catalog.my_db.device_temperature
|(
| device_id int,
| operation string,
| temperature double,
| ts timestamp
|)
|using iceberg
|tblproperties (
| 'format-version' = '2',
| 'write.delete.mode' = 'merge-on-read',
| 'write.update.mode' = 'merge-on-read',
| 'write.merge.mode' = 'merge-on-read',
| 'write.metadata.delete-after-commit.enabled' = 'true',
| 'write.metadata.previous-versions-max' = '100'
|)
|""".stripMargin
)
次に更新処理とは別プロセスとしてメンテナンスを実施する app を追加した。
通常の更新処理の mini batch の中にメンテナンスを組み込んでもよかったのだが、そうすると mini batch が遅れる可能性がある。
運用を考えてもメンテナンス用の処理は別で実行できるようになっていた方がいいだろう。
Iceberg は後述の1点を気をつければ並列書き込みが可能であるため、別プロセスで実施する方針とした。
while (true) {
println("Execute compaction")
retry(3) { () =>
spark
.sql(
"""call my_catalog.system.rewrite_data_files(
| table => 'my_db.device_temperature',
| strategy => 'binpack'
|)
|""".stripMargin
)
.show(truncate = false)
}
val ts = Timestamp.from(Instant.now().minusSeconds(20 * 60))
println(s"Expire snapshots older than ${ts.toString}")
retry(3) { () =>
spark
.sql(
s"""call my_catalog.system.expire_snapshots(
| table => 'my_db.device_temperature',
| older_than => timestamp '${ts.toString}',
| retain_last => 20
|)
|""".stripMargin
)
.show(truncate = false)
}
Thread.sleep(10 * 60 * 1000)
}
無限ループによりおよそ10分に1回、それぞれ procedure 呼び出しにより compaction と snapshot 削除が実行されるようになっている。
ここで retry() は自前の実装だが、名前のとおり失敗しても指定回数まで retry するというものになっている。
なぜ retry が必要かというと、Iceberg は並列した書き込みができるが lock などは取らず、楽観的な実行となっている。(optimistic concurrency)
一連の書き込み処理の準備が終わって最後に commit するときに、その table が他のプロセスにより更新されたことがわかると失敗となる。
実際に retry なしの場合は次のようなエラーが出ることがあった。
[error] java.lang.RuntimeException: Cannot commit rewrite because of a ValidationException or CommitFailedException. This usually means that this rewrite has conflicted with another concurrent Iceberg operation. To reduce the likelihood of conflicts, set partial-progress.enabled which will break up the rewrite into multiple smaller commits controlled by partial-progress.max-commits. Separate smaller rewrite commits can succeed independently while any commits that conflict with another Iceberg operation will be ignored. This mode will create additional snapshots in the table history, one for each commit.
このメッセージでは partial-progress.enabled の設定が推奨されているが、今回の問題設定はそもそも細かい更新だったのでちょっと違うかなというところで設定していない。
これを設定したところで retry 的な配慮は結局必要になるというのもある。
メンテナンスの実行結果
以上のように実装した2つの処理を並列実行した。
- 30秒に1回、table を更新
- 約10分に1回、table をメンテナンス
2日以上これをまわしっぱなしにした。
Compaction の効果
select 文を実行したところ、数秒で完了した。
compaction を実施する前は一晩更新を続けた後の select で6分かかっていたので、かなり速くなったと言える。
compaction により差分の merge のコストが小さくなったからだ。
OLAP ならこれぐらいで十分だろう。
Snapshot の削除
metadata file は JSON 形式になっており、次のような形で利用可能な snapshot の情報が記載されている。
{
...,
"snapshots": [
{
"sequence-number": 25,
"snapshot-id": 8639168923204820422,
"parent-snapshot-id": 5556833698284258695,
"timestamp-ms": 1684722810993,
"summary": {
"operation": "overwrite",
"spark.app.id": "local-1684722133108",
"added-data-files": "5",
"added-position-delete-files": "4",
"added-delete-files": "4",
"added-records": "26",
"added-files-size": "13020",
"added-position-deletes": "27",
"changed-partition-count": "1",
"total-records": "141",
"total-files-size": "52397",
"total-data-files": "10",
"total-delete-files": "25",
"total-position-deletes": "51",
"total-equality-deletes": "0"
},
"manifest-list": "data/warehouse/my_db/device_temperature/metadata/snap-8639168923204820422-1-7ea46920-6ac3-444d-aed1-8dbc8d0c24fd.avro",
"schema-id": 0
},
...
],
...
}
最新の metadata file に含まれる snapshot の数をカウントしてみる。
$ cat data/warehouse/my_db/device_temperature/metadata/v6133.metadata.json | jq '.snapshots | length'
59
table は30秒に1回更新されて新しい snapshot が作られている。
それと並行して10分に1回、その時点より20分以上前の snapshot を削除しているため、snapshot の数はおおよそ40〜60ぐらいになる。(実際は compaction で作られた snapshot も入ってくるためこれより少し多くなる)
snapshot の削除が効いていることがわかった。
他の metadata file の shapshot 数も確認したが、だいたい上記の範囲におさまっていた。
metadata file の削除
metadata file の削除が効いているかも確認。
$ ls -l data/warehouse/my_db/device_temperature/metadata/v*.metadata.json | wc -l
101
create table では 'write.metadata.previous-versions-max' = '100' を指定していた。
現行 version 1 件 + 過去の version 100 件ということで期待どおりのファイル数にコントロールされていることがわかった。
雑感
compaction などのメンテナンスが期待どおりに実行されていることが確認できた。
merge on read の table を長期的に運用する場合、こういったメンテナンスの処理や設定を導入することは必須となるだろう。
Iceberg で merge on read の table を高頻度で更新するにあたり、課題だなと思ったことを3点挙げておく。
ファイル形式
Apache Hudi や Delta Lake で merge on read の table を更新する場合、ベースファイルは Parquet 等の列指向、差分ファイルは Avro などの行指向がデフォルトになっている。
直感的に少量の差分は行指向になっているのが効率がいいように思うが、一方で Iceberg でこういった形での更新ができるのかがわからなかった。
複数のファイル形式がまざっていても manifest で吸収できるので読み込みはできるはず、しかし Spark からこういった書き込みができるという記述をドキュメントで見つけることができなかった。
更新にかかる時間
以下は merge on read で table 更新を行う Spark app において、Spark web UI 上で表示される各 mini batch の実行時間を表すグラフである。
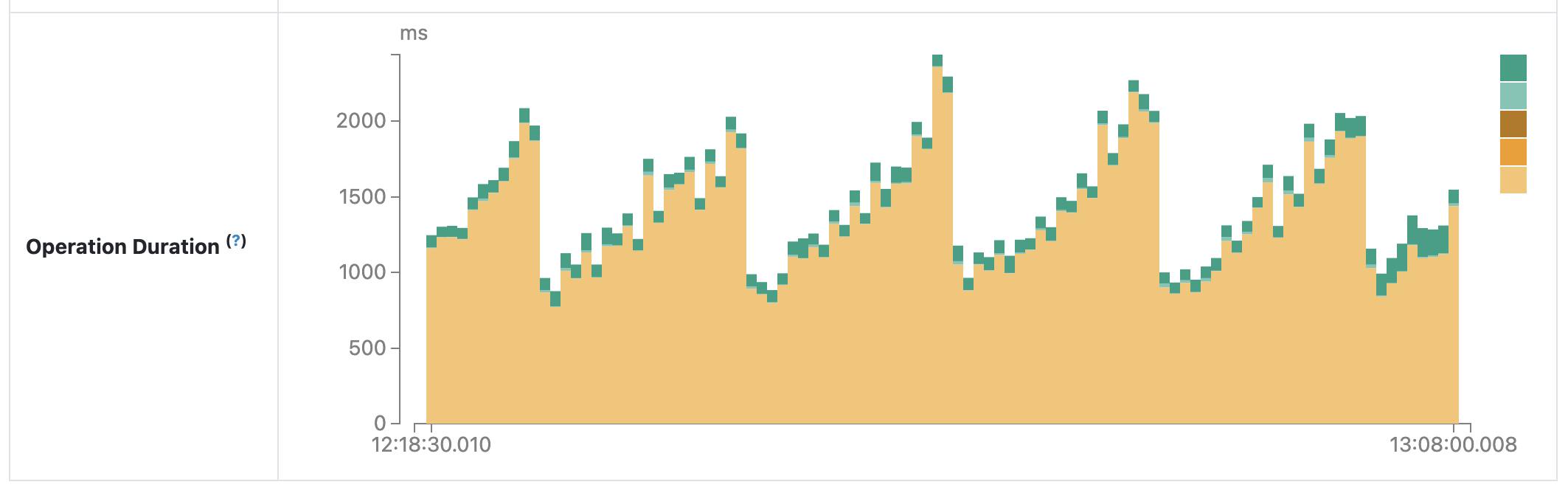
約10分周期で mini batch の実行時間が増加していき、ストンと下がるということが確認される。
この下がっている部分は compaction のタイミングであり、逆に言うと compaction しないと書き込みの時間が増大するということになる。
“merge on read” の名のとおり、本来は読み込み時に差分を merge するのであって書き込み時はそうならないはず。
しかし差分が増えると書き込み時間が増えていくというのはこの仕様に合わない。
(Iceberg のソースコードを読めばわかりそうだが、今回はそこまでやってない)
求められる技術力
Iceberg の table は ACID transaction, time travel, schema/partition evolution など運用上便利な機能がサポートされている。
一方でこれを運用していくには table format についての知見や Spark などの分散処理の知見を持つデータエンジニアのリソースが必要となってくる。
BigQuery や Snowflake などの DWH を中心としたアーキテクチャと比べて人材をそろえるハードルが高いと考えられる。
これは Iceberg というよりは Lakehouse Architecture と DWH の差だろう。
…などと課題を挙げてはみたが、総じて Iceberg はいいものだと感じた。
うまく抽象化されたレイヤーを挟むことでデータレイクのいろいろな課題を解決しており、かつ動作も比較的わかりやすい。
エンジニアリングが強い組織だと Iceberg を使って Lakehouse Architecture のも悪くなさそう。