
このポストについて
データ基盤移行について書かれた各社の技術ブログなど見かけることがありますが、割とさらっと書かれていることが多いように思います。
本当はいろんな面で苦労があり、記事に表れていない辛さや工夫などがあるはず。
ということで今自分が経験している普通の会社の普通のデータ基盤移行について、詳しく記事にしてみようと考えました。
何回かに分けてデータ基盤移行のいろいろな側面を、うまくいったこともいかなかったことも含めて書いていきます。
とはいえ現在進行形なので、全編書き終わるのはかなり先になりそうです。
データ基盤移行のシリーズ一覧はこちらから。
移行の背景
組織
まずイメージしやすいよう、どういった組織におけるデータ基盤移行なのかについて軽く触れておきます。
- 社員規模: 〜100名
- web 系の B2C ビジネス
- データチームの構成
- マネージャ: 1名 (データエンジニアリングの経験はほぼない)
- データエンジニア: 2 -> 3名 (途中で採用)
中小のベンチャー?企業ではありますが、意思決定プロセスは JTC 感があります。
私はデータエンジニアのポジションとなっており、その視点からの話であることにご留意ください。
小さい組織ということで私は移行の計画から設計、開発その他のあらゆるフェーズに中心的に関わっています。
どこもそうだと思いますが、人員的にはまあまあきびしい。
よくある中小 IT 企業のよくあるデータ基盤移行の話だと思っていただきたく。
大企業ではないのでそこまでちゃんとはしていません。
(ちなみに自分のブログで本件を記事にしていいかは上長に確認の上、OK をもらっています)
旧データ基盤
一連のポストでは移行前のデータ基盤のことを「旧データ基盤」と表記するものとします。
旧データ基盤は AWS 上で構築されており、アーキテクチャについて簡単に挙げると
- storage: S3
- ETL: Glue Job, Athena
- SQL engine: Athena
- workflow orchestration: MWAA
のようになっていました。
旧データ基盤の開発・運用側 (データエンジニア) としても、また社内の利用者側としてもいろいろと問題が挙がってきてはいました。
しかしそれをうまく集約・言語化できていないという状況でした。
そんな中でエライ人の鶴の一声で移行しようぜ!ということになり、データ基盤の移行を検討することに相成りました。
移行計画を考えるにあたり
まず考えたこと
データ基盤の移行は組織におけるデータマネジメントにおいて重要な位置づけとなるはず。
したがって単なる技術スタックの置き換えというスコープで考えるのはもったいないです。
組織のデータマネジメントの未来を想定して、戦略を持って開発・運用を進めるべきであると考えました。
そのためにはイシューを明確化しないといけません。
でもどの抽象度レベルで?
ボトムアップの戦術策定
まずは現場感覚、ボトムアップでの課題を明らかにすることを考えました。
本来は後述する戦略レベルから先に考えるべきですが、実際に目に見えている課題があり、取り組みやすかったというところで戦術のレベルから考え始めています。(良し悪しはある)
現状のアーキテクチャと運用では戦略策定への対応が難しいため、せめてそのための地ならしとして今見えている課題に対応できる状態にしたいというのもありました。
この視点でイシューを明確化するために2つのサーベイを実施しました。
データマネジメント成熟度アセスメントと利用者アンケートです。
これらを実施して整理した結果、当面のロードマップのようなものを描くことができました。
この2つのサーベイとそこから得られた結果については後ほど詳しく記載します。
ちなみにここでは「戦略」「戦術」という言葉は大雑把に使っています。
戦略の方が抽象度が高く長期、戦術の方が抽象度が低く短期のものだと思ってください。
トップダウンの戦略策定
データ戦略やデータマネジメント戦略は事業戦略と整合しているべきというのは複数の書籍で言われていますし、同業者の口からもよく聞きます。
データ戦略には、情報を利用することで競争上の優位性を確保し、企業の目標を達成するための事業計画が含まれる。組織にどんなデータが必要で、それをどのように取得し、時間の経過とともにどのように管理し信頼性を担保するか、どう活用するかなど、事業戦略に不可欠なデータの必要性を理解した上で、データ戦略を考えなければいけない。
– DAMA International (編著) 『データマネジメント知識体系ガイド第二版』, 第1章 データマネジメント, 日経BP, 2018年
データ戦略が意味を持つには、企業のミッション、ビジョン、戦略、KPIとの整合性が不可欠です。組織の目標は、通常はミッションからビジョン、財務目標、部門目標へと段階的に具体化し、最終的にはソーシャルメディア目標や販売目標などのチームごとの具体的な目標へと落とし込んでいきます。
– Harvinder Atwal (著) 『実践DataOps』, Chapter 2 データ戦略, 翔泳社, 2024年
戦術レベルのロードマップに対して戦略とのすり合わせを行おうとしましたが、結論としてこのようなトップダウンの戦略策定は我々の組織ではうまくいきませんでした。
(つまり記事のタイトルに偽りありです…)
うまくいかなかったのには2つの理由があります。
まず第一にマネジメントのケイパビリティです。
多少のサポートにより経営戦略とひもづけてデータ戦略を主体的に立案することができるような人材が、残念ながらマネジメント層にいませんでした。
むしろプラットフォームなどというものはビジネスから遠いところにあると思われていて関心は薄いです。
難しいところです。
第二に、上記の前提があるとしてデータエンジニア側からうまく戦略策定を誘導することができませんでした。
第一の理由は悲観的に書かれているように見えるかもしれませんが、世の中小規模の組織では同様の状況になっていることが多いと思われます。
これを嘆いていてもどうにもなりません。
ということでエライ人に対してデータ基盤に関係しそうな経営戦略を教えてくれ、それとデータ基盤の戦略を関連させたいというお願いをしてみましたが「?」という雰囲気がリモート会議の画面から漏れ出ていました。
またマネージャに対してデータ基盤としてのビジョンを提案したこともありますが、なんで急にそんなお題目みたいなこと言うの?という感じでした。
今これを書いてて思ったのは、おそらく2人ともデータ基盤移行を単なる技術スタックの置き換えだと思っていたのかもしれません。
関係性の構築が不十分、かつデータ基盤移行で目指すところの意味をあまり議論できていなかったということが反省点です。
戦術策定のためのサーベイ
データマネジメント成熟度アセスメント (DMMA)
組織のデータマネジメントの進め方の指針として DMBOK Pyramid (Peter Aiken’s Framework) があります。
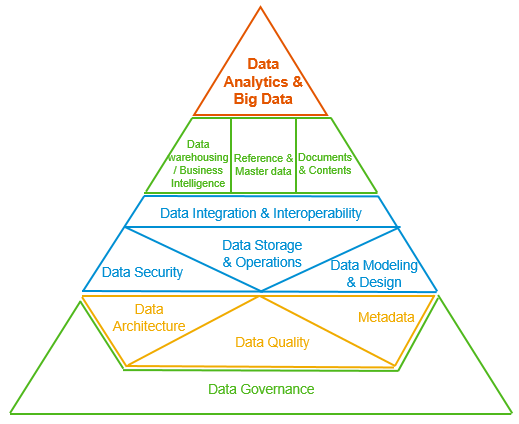
Peter Aiken’s Framework, Why HR Data Management Strategy is important in your HR Transformation | SAP Blogs (元ネタは DMBOK2)
自分たちの立ち位置としてこの図の Phase 1 (青色) と Phase 2 (黄色) の間ぐらいだとなんとなく考えていましたが、社内のステークホルダーに話すためには定量的に立ち位置を確認する必要があります。
これをやるのがデータマネジメント成熟度アセスメント (DMMA: Data Management Matulity Accessment) です。
DMMA は DMBOK2 にも記載されている、組織のデータマネジメントの現状を評価する方法です。
こちらの記事も参考にしてください。
ここで困ったのがアセスメントのための具体的な質問をどうやって用意するかです。
DMBOK2 に記載されているのはリンクがもう古かったり、大げさだったりで使いにくいものばかりでした。
そこで ChatGPT を利用しました。
(プロンプト力はあまり高くないですが) 例えば次のように指示しました。
DMMA で DAMA DMBOK のそれぞれの知識領域について定量的にスコアリングするために、質問集を用意しようと考えています。
定量的に評価したいので知識領域ごとに closed question が複数必要です。
DAMA DMBOK 第3章「データガバナンス」を評価するための質問をいくつか挙げてください。
次のような結果が得られました。
DAMA DMBOKの第3章「データガバナンス」を評価するための質問を考える際、組織のデータガバナンスの成熟度と効果を定量的に評価するために、以下のようなクローズドクエスチョン(選択肢から選ぶ質問)を用意することが考えられます。これらの質問は、データガバナンスのさまざまな側面をカバーし、回答者が具体的な選択肢から選ぶ形式で答えられるようになっています。
- データガバナンスポリシーの存在: 組織には明確なデータガバナンスポリシーがありますか?
- データガバナンスフレームワークの実装状況: 組織のデータガバナンスフレームワークは完全に実装されていますか?
…
割といい感じではないでしょうか?
このようにしてアセスメントのための質問を作成していきました。
質問への回答はデータエンジニア2名でそれぞれ実施し、5段階評価で回答します。
スコープはもちろん組織全体ではなくデータ基盤です。
それらを相談してすり合わせた結果を DMMA の結果としました。
各知識領域ごとの各質問に対するスコアが得られ、結果として以下のようなレーダーチャートが得られます。
(こちらのレーダーチャートは本当の結果ではなく、例となっています)
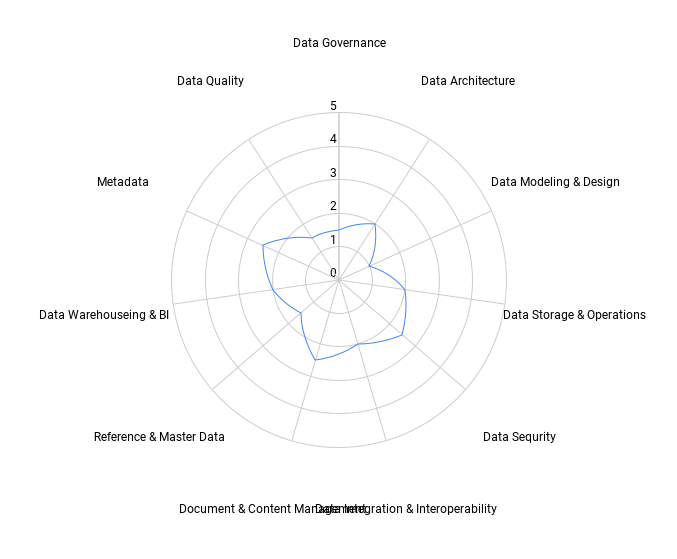
予想はしていましたが、この時点でのスコアは低いです。
DMMA は定期的に実行してデータマネジメントの進捗を確かめるものなので、データ基盤移行が終わったあとにどうなるかが楽しみです。
利用者アンケート
DMMA はデータエンジニアで実施しているため、どちらかというと運用側の視点です。
利用者側の視点も得るため、社内のデータ基盤の利用者に対してアンケートを実施しました。
ここでも ChatGPT が活躍します。
私は IT 企業のデータエンジニアであり、社内のデータ基盤の刷新を検討しています。
その参考とするために、社内のデータ基盤利用者に対して Google Form でアンケートを実施しようとしています。
アンケートの目的は、データエンジニアが把握していないデータ基盤の利用ニーズを理解することで、その気付きを新しいデータ基盤の技術スタック選定や運用改善に活かしたいと考えています。
アンケート項目を考えてください。
この結果を元に多少修正し、Google Forms にしてアンケートを作成しました。
利用者に広くアンケートへの回答を依頼し、ご理解もあって思ったより多くのご回答をいただくことができました。
ここで面白かったのが、DMMA 結果における課題感とアンケート結果の課題感が概ね一致していたことです。
当たり前と言えば当たり前なのですが、データエンジニアが利用者側の課題をある程度把握できていると見ることができます。
ロードマップ作成
サーベイ結果を集約して整理したところ、組織のデータまわりでは数個の大きな課題があることがわかりました。
例として1つ挙げると「データ品質テストの不足」です。
アンケート結果を集約すると、こういった大きな課題にまとめることができました。
解決すべき課題がわかった上で、データ関連の技術スタック、およびそれによる解決可能性を検討しました。
その上で次のような形で大まかなロードマップを定めました。
flowchart LR
current(["現状"]) --> dwh["DWH 製品の導入"]
subgraph rearchitecture["データ基盤のリアーキテクチャ"]
dwh --> dbt["dbt の導入"]
end
dwh --> solution_1["solution 1"]
dwh --> issue_1>"issue 1 の解決"]
solution_1 --> issue_1
dbt --> solution_2["solution 2"]
solution_2 --> issue_2>"issue 2 の解決"]
dbt --> issue_3>"issue 3 の解決"]
current --> solution_4_1["solution 4-1"]
solution_4_1 --> issue_4>"issue 4 の解決"]
current --> solution_4_2["solution 4-2"]
solution_4_2 --> issue_4
dbt --> solution_5["solution 5"]
solution_5 --> issue_5>"issue 5 の解決"]
dbt --> implement_test["データ品質テストの実装"]
implement_test --> improve_quality>"データ品質テストによる品質改善"]
(図が見にくい場合はライトモードにしてください)
DWH 製品を新しく導入すること、および dbt の導入により多くのソリューションが実現できると考えました。
よってこの2つをまとめてデータ基盤のリアーキテクチャとみなし、当面はここに取り組んでいくことにしました。
ここまでの課題と今後の対策
ここまでの取り組みで一番大きな課題だと感じたのは組織としてのデータマネジメント戦略をトップダウンで作れていないことです。
マネジメント層を含めほとんどの人が「データマネジメント?ナニソレオイシイノ?」という状態だったため、せめて組織にデータマネジメントを浸透させたいと考えました。
組織が今よりもう少しデータマネジメントの言葉を使って会話できるようになりたい。
そこで社内で DMBOK2 の輪読会を開催することにしました。
幸い思ったより多くの方に関心を持っていただくことができ、その中にはマネージャ数名も含まれています。
輪読会は週1回開催で発表者を決め、DMBOK2 を1章ずつ読み進める形としています。
量が多く時間はかかりましたが、年末もしくは年明けぐらいに終わる見込みです。
これが終われば組織がデータマネジメントを学習でき、一段抽象度の高い戦略の議論をする下地ができるのではと考えています。
次回予告
次回のポストでは DWH (という呼称は適切でないかもしれませんが) の技術選定、そしてその結果を受けての予算獲得について書く予定です。
以上、現場からでした。