
このポストについて
データ基盤移行について書いていくシリーズです。
シリーズ一覧はこちらから。
前回 Part 2. 技術選定編では技術選定について書きました。
今回はそれを踏まえた結果としてどのようなアーキテクチャになったかを書きます。
スコープ
前回の記事ではプラットフォームとして Databricks を選定したことやその経緯について記載しました。
一方、それより詳細な技術スタックを含むシステムアーキテクチャについては示していませんでした。
例えばデータ基盤では通常次のような技術スタックについて考える必要があります。
- データ取込
- workflow orchestration
- ELT (or ETL)
- storage
これらについて述べ、またデータ基盤の階層構造についても説明します。
システムアーキテクチャ
データ基盤のシステム・アーキテクチャです。
よく混同されがちですが、データアーキテクチャではありません。
AWS + Databricks の構成をベースとして構築されています。
概要図
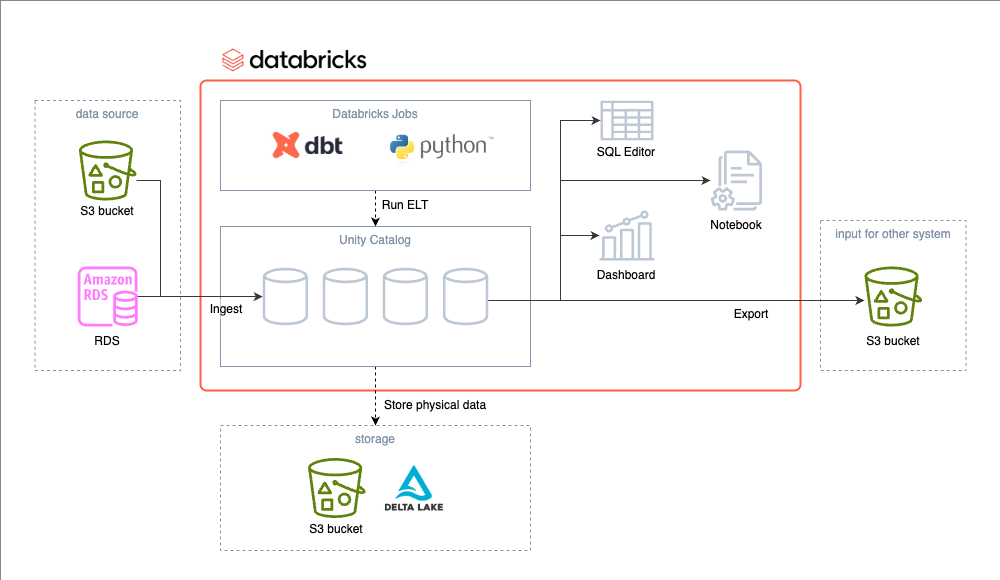
データ取込
現時点ではデータソースとしては S3 に置かれた半構造化データ (JSON)、RDS がメインとなっています。
これら2つの取込方法について述べます。
まず、S3 のデータは SQL の copy into 文により取り込んでいます。
Auto Loader を使う方が Databricks 的でありそれも検討したのですが、schema evolution や冪等性など検討した結果として copy into を採用しました。
RDS からのデータ取込は foreign catalog 経由で行います。
foreign catalog は RDS など Databricks の外部の DB に対して、Databricks からクエリを投げることができる仕組みです。
いわゆる federated query であり、Databricks 上で Databricks の table と RDS の table を join できたりします。
現時点では Fivetran や Airbyte などは使っていませんが、今後検討するかもしれません。
また、Databricks さんとしても Lakeflow Connect としてこの領域を頑張り始めたので、そちらも期待しています。
Workflow Orchestration
データパイプライン全体の処理の依存関係を管理する workflow orchestration には Databricks Jobs を使いました。
Databricks 上でもっともライトに使える workflow orchestration ということでこれにしています。
Databricks Jobs では job の中に複数の task があり、その task の依存関係で処理の流れが構築されます。
Apache Airflow などと似たようなものイメージしていただければと。
一方で job の定義は Airflow と違い、Terraform などの IaC で行うことになります。
これは少し面倒ですね。
我々の job では後述の dbt やちょっとした Python コードが実行されています。
ELT
ELT には dbt を使っています。
Databricks には DLT (Delta Live Table の略。こっちの dlt とは別物) という dbt と似たことができる機能がありますが、dbt を選びました。
dbt 周辺のエコシステム、および dbt の方が移植性があることが選定理由です。
Databricks というとかつては Apache Spark のイメージが強かったのですが、最近は dbt から SQL で使うケースも多いみたいです。
Spark で実装もできなくはないのですが、Spark のアーキテクチャを理解してパフォーマンスチューニングまでできるレベルのエンジニアは少ないので直接 Spark のコードを書く方針は取りませんでした。
実質的には Photon という Spark の技術をベースにしたエンジンで SQL が実行されるわけではありますが。
データパイプラインの大半を dbt でやっておけば、仮に Databricks Jobs より他のがいいってなったときでも workflow orchestration の変更が比較的容易だという打算もあります。
…なんですが、結局 dbt 以外の「ちょっとした Python コード」も拡大しているのでそんな容易にもならいのでしょうね、きっと。
以下余談。
旧データ基盤では ETL で Glue Job が使われていましたが、Spark のアーキテクチャを理解していないエンジニアによって作られていたためひどいパフォーマンスでした。
Spark では SQL-like なインターフェースが提供されておりプログラミングモデルとしてはとっつきやすいのですが、アーキテクチャを理解して実装しないとすごく無駄な動きをしてしまったりします。
そういうこともあり、SQL + dbt の枠組みでやるぞとなりました。
Data Catalog
Databricks を使うのであれば data catalog としては Unity Catalog を使うのが自然でしょう。
Unity Catalog は Databricks の中でも中核的な機能であり、全貌を説明するのは難しいです。
data catalog における table や column の description は dbt project の YAML でバージョン管理されています。
Storage
データ基盤のユーザーが意識することは少ないですが、データの実体は我々が管理する S3 bucket 上に配置されます。
このように storage が computing のリソースから分離されていることにより、データ容量と処理量のそれぞれに応じて別々にスケールすることができます。
データは Delta Lake 形式で保存されており、Unity Catalog 経由で SQL などで利用されます。
Delta Lake 形式であることにより従来の data lake にはなかった ACID transaction が実現され、lakehouse architecture の体をなします。
lakehouse architecture については以下の論文がおすすめです。
データの階層構造
アーキテクチャかというと微妙ですが、ELT によりデータが加工されて作られる階層構造についても触れておきます。
概要図
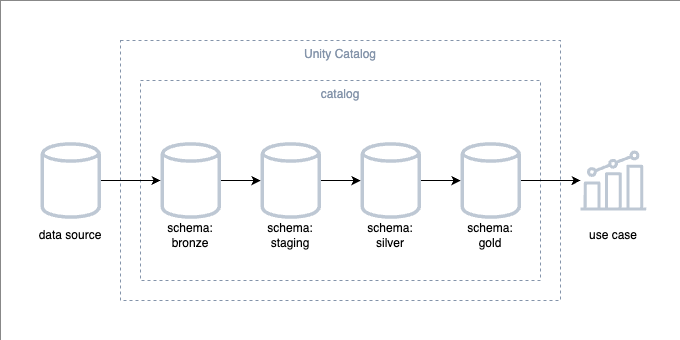
全体
このようにデータ基盤内でデータの処理過程を階層に分けるというのはよくある話ですが、階層の分け方や命名は各組織で結構違いがあると感じています。
ここでは medallion architecture と dbt best practice を参考にして各階層を定義しました。
- メダリオンアーキテクチャ (medallion architecture) | Databricks
- How we structure our dbt projects | dbt Developer Hub
まずは medallion architecture について。
下記の記事の図を見てほしいのですが、データ基盤における各階層の命名の仕方は本当にいろいろあります。
その中から medallion architecture を選んだわけですが、medallion architecture における各階層の命名には以下のメリットがあります。
- bronze, silver, gold という命名は誰にでもわかりやすく、またこの順で発展していることも示せている
- data lake, data warehouse など、近い分野において別の意味で使われることのある言葉は使われていない
- (Databricks が提唱している考えであり、Databricks のコンテキストで話がしやすい)
これに加え、dbt best practice から “staging” という層を追加しています。
dbt を使うことが決まっていたことから dbt の best practice を見ていましたが、dbt が推奨する階層において medallion architecture の定義と一致しないのが staging でした。
よってその層を medallion architecture に追加しました。
ちなみに各階層は Databricks の schema として実装されます。
Bronze Layer
この階層ではほぼ未加工の状態で取り込んだだけのデータを保持します。
「ほぼ」と書いたのは、データソースや load された時刻など少しのメタデータを加えるためです。
これらのメタデータは問題発生時の調査や監査に使用されます。
Staging Layer
この階層では各 column の簡易な変更のみを行います。
この後の処理がしやすいよう、データの体裁を整えるようなイメージです。
簡易な変更とは例えば以下のような処理です。
- データ基盤の命名規則にもとづいた column の命名の変更
- 型変換 (ex. string 型で渡された日付を date 型に)
- 単位の変換 (ex. フィートをメートルに)
- struct のフラット化
ただしここではビジネスロジックの適用や複雑な計算、join や group by などは行いません。
他の階層は主に table として実装しますが、この階層のみは view として作ります。
Silver Layer
この階層ではデータを汎用的な分析に利用できるレベルにします。
ビジネスロジックにもとづくフィルタリングや結合、複雑な処理、重複排除などを行います。
Gold Layer
この階層では各ユースケースに合わせたデータを生成します。
特定のレポートや他のシステムへの input のため、必要に応じて集計などを行います。
その他
本来であれば silver layer あたりで dimensional modeling や data vault などを取り入れたいのですが、現状ではできていません。
移行前の旧データ基盤ではそういったデータモデリングが行われておらず、データ基盤のアーキテクチャの移行と合わせてデータモデリングの考えを導入するのはハードルが高すぎるとなったためです。
このあたりは今後の課題です。
次回予告
今回アーキテクチャの話ができたので、開発するものがイメージしやすくなったのではと思います。
次は CI/CD の話でもしますかね。