
このポストについて
データ基盤移行について書いていくシリーズです。
シリーズ一覧はこちらから。
前回 Part 4. AI ワークフローで移行作業効率化編では移行するための苦労と効率化について書きました。
今回はがらっと変わって IaC と CI/CD について書きます。
スコープ
今回は開発寄りの話です。
データ基盤の構築にあたり Terraform を使って IaC (Infrastructure as Code) を実現し、さらにそれに基づいて GitHub Actions による CI/CD (Continuous Integration & Continuous Derivery) 環境を作ったという話をしていきます。
IaC で作りたいアーキテクチャは AWS 上の Databricks 環境とその周辺です。
アーキテクチャについて詳しくは Part 3. アーキテクチャ編などをご参照ください。
だいたい以下の図のような話です。
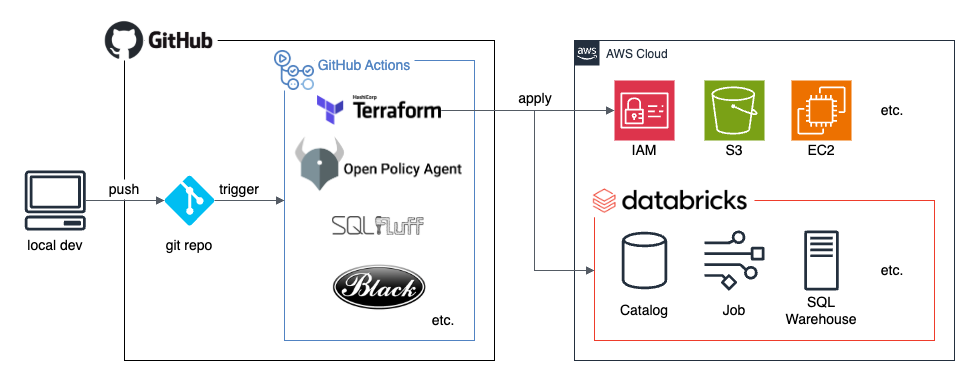
お気持ち表明
こんにちは、初手で絶対に CI/CD 環境を構築するマンです。
初手で絶対に CI/CD 環境を構築するマンは、初手で絶対に CI/CD 環境を構築するぞ!という強い気持ちを持っています。
Databricks 上にデータ基盤を構築するにあたり、他社事例でインフラ構築を自動化していないケースを見たこともあります。
しかし我々のチームでは PoC 終了後の構築最初期から IaC としてインフラをコード化し、それを CI/CD の仕組みで自動でデプロイすることを決めていました。
次のような理由からです。
- リリースの数だけ自動化のリターンがあるので、最初から自動化しておくのが最もリターンが大きい
- チームにはジュニアなメンバーもおり、手動の運用はオペミスや production, staging などの環境差発生のリスクが大きい
- 社内で Terraform や GitHub Actions などがよく使われており、導入できる下地があった
まだ Databricks にそこまで慣れていない導入初期にこれらの仕組みを入れるのはそれなりにたいへんです。
しかしそのたいへんさ以上のメリットがあると判断しました。
データ基盤というプロダクトにおいて CI/CD は IaC とセットであると言えます。
AWS や Databricks のレイヤーをコード化してコマンドでデプロイできるようにすることにより、CI/CD の運用が可能となります。
IaC
Terraform
IaC の仕組みとしては Terraform を使います。
Databricks 独自の Asset Bundles という選択肢もありましたが、次のような理由から Terraform を使うことにしました。
- (前述のとおり) 社内に Terraform の知見があり、詳しいエンジニアもいて頼ることができる
- Databricks の環境は AWS 上に構築されており、データの取込やエクスポートまわりも含めて何かと AWS のリソース作成も必要となる
- チームとして Databricks のリソースだけ管理するわけではない
Terraform には Databricks Provider があり、Databricks の様々なリソースを作ることができます。
例えば我々の Terraform project では次のような Databricks のリソースを管理しています。
- 各種 database object
- metastore
- catalog
- schema
- 権限まわり
- user, service principal, group
- 各種リソースへの権限の割当
- データパイプライン関連
- Lakeflow jobs (Databricks 独自の Airflow-like な workflow orchestration)
- SQL warehouse
- その他
- 各種設定
- 必要かつ Terraform で管理できるものは何でも
Project 構成
Terraform project の構築は基本的に公式の style guide に基づくようにしました。
例えばディレクトリ構成も以下の style guide の推奨構成をベースにしています。
├── modules
│ ├── compute
│ │ └── main.tf
│ ├── database
│ │ └── main.tf
│ └── network
│ └── main.tf
├── dev
│ ├── backend.tf
│ ├── main.tf
│ └── variables.tf
├── prod
│ ├── backend.tf
│ ├── main.tf
│ └── variables.tf
└── staging
├── backend.tf
├── main.tf
└── variables.tf
dev/, prod/ など各環境のディレクトリがあり、通常 terraform plan や terraform apply などのコマンドはこの各環境のディレクトリから実行されます。
ほぼすべてのリソースは Terraform module として moudules/ 以下で定義され、各種環境からはそれを呼び出して利用しています。
module をどういった単位でまとめるかというところが難しいところで、実際に悩むこともよくあります。
ベースとなる考え方としては公式の Module creation - recommended pattern: Scope the requirements into appropriate modules | Terraform | HashiCorp Developer があります。
簡単に言うと一緒にデプロイされるもの・権限を持つグループが同じもの・リソース寿命が同じものを同じ module にします。
AWS が CloudFormation の best practice でよく似たことを言っていたりもします。
よくやりがちなこととして同じタイプのリソースを同じ module に集めるというのがありますが、多くの場合ではそれは逆に bad practice だと考えています。
再利用性を考えてうまく module を設計すると運用が楽になります。
例えば外部システムから Databricks のデータにアクセスする設定のための module を構築し、外部システム名を入れるだけで次のようなことができるようにしました。
- service principal (システムからアクセスするための user のような概念) の作成
- service principal の認証のための secret 情報の作成
- secret 情報の AWS Systems Manager Parameter Store への登録
- service principal 用の SQL warehouse の作成
- SQL warehouse の権限設定
あとはその外部システム固有の権限設定を行えば、外部システム管理者に Parameter Store の情報を教えるだけで利用できるという寸法です。
このように Databricks と AWS のリソースを1つの module に含めることができるのも Terraform の利点です。
Databricks × Terraform の注意点
…というように Terraform project を構築して運用しているのですが、Databricks のリソースを Terraform で管理するにあたってはいくつか注意点があります。
- Terraform で扱えないリソース
- dbt によるリソース管理
- 古い名前のリソース
- リソース間の依存関係
Terraform で扱えないリソース
すべての Databricks リソースが Terraform で扱えるわけではありません。
例えば Unity Catalog におけるユーザー定義関数などがそれにあたります。
こういったものは別の仕組みで管理する必要があります。
dbt によるリソース管理
一方で table や view は Terraform で扱うことができますが、我々の Terraform project ではこれらは扱っていません。
ELT の仕組みとして dbt を導入しており、table や view は dbt で作られるためです。
Terraform 以外で管理したいリソースもあるということです。
古い名前のリソース
Databricks ではときどきサービスや各種概念の名前が変わりますが、Terraform リソースの名前は古いままになっていることがあります。(おそらく互換性のため)
例えば SQL warehouse を作るための Terrafrom リソースは SQL warehouse の古い名前である databricks_sql_endpoint となっています。
なので Terraform のコードを読むときに気をつける必要があります。
リソース間の依存関係
Databricks に限ったことではないですが、「A を作った後でないと B を作れない」といったような依存関係がリソース間にある場合があります。
多くの場合はリソース B の argument として A の attribute を指定することになり、Terraform により暗黙的によしなに依存関係に配慮がなされます。
しかしまれに実質的には依存関係があるのに暗黙的な依存関係が作られないことがあります。
そういった場合は depends_on で明示的に依存関係を示してやる必要があります。
CI/CD
GitHub Actions
さて、IaC が Terraform project で構築できたわけですが、ここまでできていれば CI/CD に IaC を組み込むのは難しくありません。
CI/CD のフレームワークとしては GitHub Actions を採用しました。
組織として GitHub 上でコード管理をしており、GitHub Actions もよく使われていたからです。
Terraform project への変更を含む pull request が merge されると、GitHub Actions がトリガーされて terraform apply が実行され、インフラの変更が production 環境へと反映されます。
(ちなみに pull request のレビュー前に staging 環境での検証を義務付けているので、production 環境への反映で失敗することはまれにしかありません)
つまりリリース作業に手動のオペレーションは極力含まれないようにしています。
CI/CD でやること
GitHub Actions の中では terraform apply 以外に次のようなことをやっています。
- Terraform 関連
terraform init,terraform validateによるチェック- TFLint による linting
- Open Policy Agent によるリソースポリシーのチェック
- 例えば S3 bucket 名が命名ルールに従っているかなど、様々なチェックができる (楽しいけど Rego がむずい)
- dbt 関連
- SQLFluff による linting
- dbt-osmosis による table や column の description のチェック
- dbt project の Databricks 環境へのデプロイ
- Python 関連
- Flake8, Black による linting
- unit test
- Python project の Databricks 環境へのデプロイ
このあたりはまだまだ充実させたいと考えています。
例えば dbt で複雑な処理を実装した場合の unit test がまだありません。
dbt の unit test の導入は現在検討中で、近いうちに GitHub Actions から実行できるようにしようとしています。
pre-commit
CI/CD に含めるかは微妙ですが、GitHub Actions でやっているチェックのうちのいくつかはローカル開発環境の pre-commit により、git commit 時にもチェックしています。
変更を git push してから GitHub Actions でチェック失敗に気づくよりは、ローカルで気付ける方がリードタイムが短く楽だからです。
ちなみに正規のチェックは GitHub Actions であり、pre-commit はあくまで補助的なものです。
pre-commit は開発者が設定していなかったり git commit --no-verify されたりしたら機能しないので、信頼性の面で GitHub Actions の方が上です。
運用はどんどん楽に、かつメンバーのスキルに依存せず安定して行えるようにしていきたいです。
ちゃんとやっている組織の方からすると普通のことかもしれませんが、地道に改善していく所存です。
次回予告
次はメタデータの話でもしようかな。