
このポストについて
データ基盤移行について書いていくシリーズです。
シリーズ一覧はこちらから。
前回 Part 5. IaC と CI/CD 編では Terraform による IaC とそれに基づく GitHub Actions による CI/CD について書きました。
今回はみんな大好きメタデータです。
メタデータとはなんぞやという方はこちらの記事も御覧ください。
スコープ
実は今回のデータ基盤の移行のその前から OpenMetadata によるメタデータ管理を始めていました。
その導入、およびそこからの Databricks への移行について紹介します。
DMBOK2 によるとメタデータは3種に分類され、
- ビジネスメタデータ
- テクニカルメタデータ
- オペレーショナルメタデータ
がありますが、ここでは主にビジネスメタデータについて扱います。
あまり新規性のある話にはなりませんが、ケーススタディとしてご参考になれば。
メタデータ管理の導入
私の所属する組織がどのようにメタデータを導入していったか、大まかな流れは次のようになっています。
- 暗黒時代
- OpenMetadata の導入
- Databricks への移行
それぞれのフェーズについて述べていきます。
1. 暗黒時代 (2022年〜)
「メタデータ?ナニソレオイシイノ?」という状況がスタート地点です。
私が今の組織にデータエンジニアとして join した直後はまだ組織内で「メタデータ」という言葉が認知されておらず、「ビジネスメタデータがなくて不便」という課題すらも認識されていませんでした。
とはいえ join の直後、データ基盤のデータを眺めてみてもこれらが何なのか人に聞かないとわかりません。
table や column の命名がわかりやすいものになっていない 1 ことが、データ理解しにくさに輪をかけている状況でした。
この時点ではこの記事のタイトルにもあるデータ基盤移行はまだ始まっておらず、旧データ基盤を使っていました。
旧データ基盤では Athena や Glue Job でデータを処理しています。
したがって Glue Data Catalog にビジネスメタデータを置けないかと検討しましたが、難しそうだなという結論になりました。
たしか当時は日本語が扱えないとかだったような。(うろ覚え)
2. OpenMetadata の導入 (2023年〜)
ということでメタデータツールの導入を検討し始めました。
いくつか候補となるツールを調査し、機能性や扱いやすさ等から OpenMetadata の SaaS 版を選定しました。
OpenMetadata は様々なデータアセットに対する様々なメタデータを登録・管理・閲覧できるメタデータプラットフォームです。
web UI から Athena の各 table および各 column に対してビジネスメタデータを登録することができます。
以下は OpenMetadata のデモ画面です。
この例では Snowflake 上にある dim=customers という table の画面を開いています。
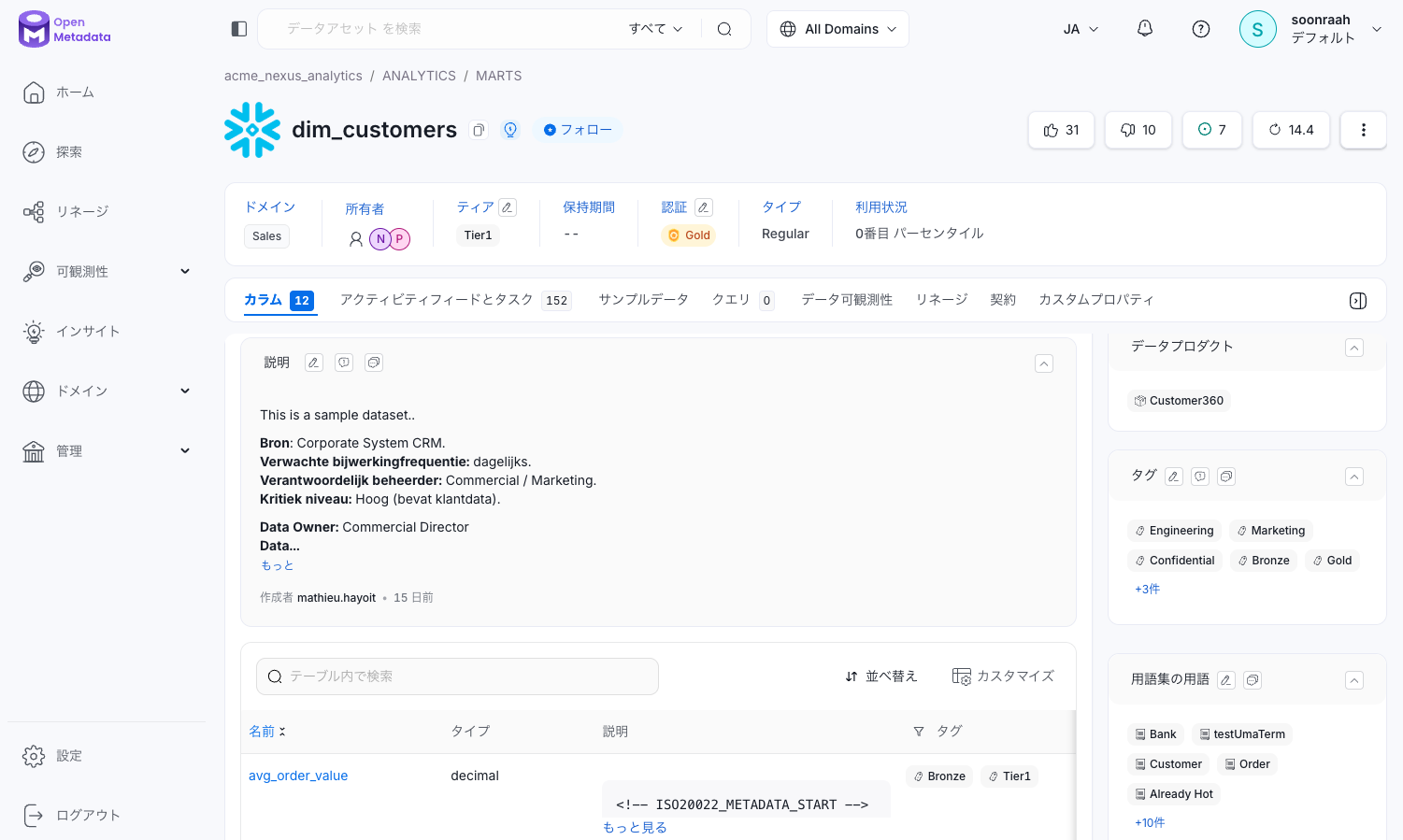
さて、ツールは決まったものの中身のメタデータはどうやって用意するか?
メタデータの作成は作業量としても大きく、またデータチームだけで行えるものでもありません。
他チームの協力も不可欠ですが、嫌な顔されないだろうか…
そこで参考になったのが次の勉強会でした。
こちらの勉強会では各社の方々がメタデータ導入の苦労話をお話されていました。
それを参考にさせていただき、以下の方針で進めました。
- 優先度
- すべての table を対応するのはきつい
- 各 table の利用頻度を調べ、上位のものだけを対象にする
- データオーナー
- OpenMetadata では table ごとに owner の項目を設定できる
- これを先に決めてしまいメタデータの責任者とした
- 主にソースのデータを作っているチームとした
- 根回し
- まずエラい人に賛同してもらった上で他チームに余裕を持って依頼
- (書いてみたら普通の仕事の段取りっすね…)
各チームに依頼した結果、以外と嫌な顔をされずに作業をしていただくことができました。
ありがたい。
データがわからんという潜在的な課題をわかっていただいていたのかもしれない。
この中でもデータオーナーを決めることができたのは良かったです。
というのも、運用フェーズでメタデータに対する問い合わせをデータチームで受けるのではなく、データオーナーに回せるからです。
3. Databricks への移行 (2025年〜)
という感じで OpenMetadata が運用されていたのですが、メタデータの文脈とは別でこのシリーズでも扱っているデータ基盤本体の移行が進んでいました。
Databricks + dbt 中心のアーキテクチャへの移行です。
このあたりの経緯についてはシリーズの過去記事を参照。
Databricks には Unity Catalog というデータカタログがあり、ビジネスメタデータを扱うことができます。
一方で OpenMetadata には次の課題があり、メタデータを Databricks に移行する向きとなりました。
- SaaS 版を使っていたがコストがかかる
- その割に社内での利用者が少ないことがわかった
- SQL 等のデータ操作と別画面 (OpenMetadata の web UI) を開かないといけない
2点目については主にデータアナリストの利用を想定していたのですが、入社してしばらく経つとメタデータはあまり見なくなってしまうようです。
組織として各ドメインのチームに専任のデータアナリストがいる構成でしたが、専任だといつも見る table が決まっているということでしょう。
メタデータは Databricks の UI 上で管理することも検討しましたが、結局 dbt の YAML で管理することにしました。
UI 管理だとエンジニア以外でも更新できて良いのですが、Databricks ではそのために table に対する MODIFY 権限が必要になってしまいます。
この権限があるとデータも変更できてしまうわけですが、エンジニア以外がそれをするのはちょっとな…ということで dbt YAML となりました。 2
ちなみにこの作業はまだ現在進行形です。
OpenMetadata のメタデータは API アクセスもできるので、API で取得して YAML を作るみたいなスクリプトでやってます。
また、メタデータ管理に dbt の YAML を用いているため dbt-osmosis も導入しました。
上流 model のメタデータを下流 model に伝播させるのに使っています。
これも前述の勉強会から参考にさせていただいています。
thx.
メタデータの今後
組織にメタデータの概念を持ち込んでから現在の運用までをざっと書きましたが、我々として今後考えるべきことも少し書いておきます。
生成 AI の文脈
エーアイエーアイの世の中ですが、Databricks も AI にかなり力を入れていて Genie Space や Genie Code など生成 AI にデータ分析をさせる機能が生えてきています。
自然言語でデータ分析をさせる、つまり text-to-SQL なわけですが、ここでビジネスメタデータが重要になってきます。
自然言語のビジネスオブジェクトを DB 上の物理モデルの概念と紐づけるのにビジネスメタデータを利用できます。
つまり AI 活用でビジネスを推進するためにビジネスメタデータの重要性が一段上に上がっているわけです。
ビジネスメタデータが整備されていなければ AI 活用の面で遅れを取ることになるでしょう。
なので今後もビジネスメタデータの量と質を担保する運用をしていく必要があります。
ビジネス以外のメタデータ
ここまで主にビジネスメタデータについて書いてきましたが、その他のメタデータについても触れておきます。
Databricks でテクニカル、オペレーショナルメタデータはある程度取れるのですが、加えて Elementary dbt package を導入しています。
Elementary は dbt project のログを収集し、オペレーショナルメタデータとして table に保存してくれます。
まだあまりちゃんと運用できていないのですが、ちょっとした調査等で役に立ちます。
最近では一部のデータ品質のモニタリングに Elementary のデータを使うことを計画しています。
オペレーショナルメタデータを運用に役立てる形を作っていきたいです。
次回予告
未定。
なんか考えときます。