
はじめに
前回のポストではデータレイクとはどういうものかというのを調べた。
今回はデータレイクの文脈でどのような OSS が注目されているのかを見ていきたい。
以下は NTT データさんによる講演資料であり、その中で「近年登場してきた、リアルタイム分析に利用可能なOSSストレージレイヤソフト」というのが3つ挙げられている。
- Delta Lake
- Apache Hudi
- Apache Kudu
これらはすべて論理的なストレージレイヤーを担う。
こちらの講演資料に付け足すようなこともないかもしれないが、このポストではデータレイクという文脈から自分で調べて理解した内容をまとめるということを目的にする。
当然 Hadoop, Hive, Spark 等もデータレイクの文脈において超重要だが、「データレイク」という言葉がよく聞かれるようになる前から普及していたのでこのポストでは触れないことにする。
Delta Lake
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads.
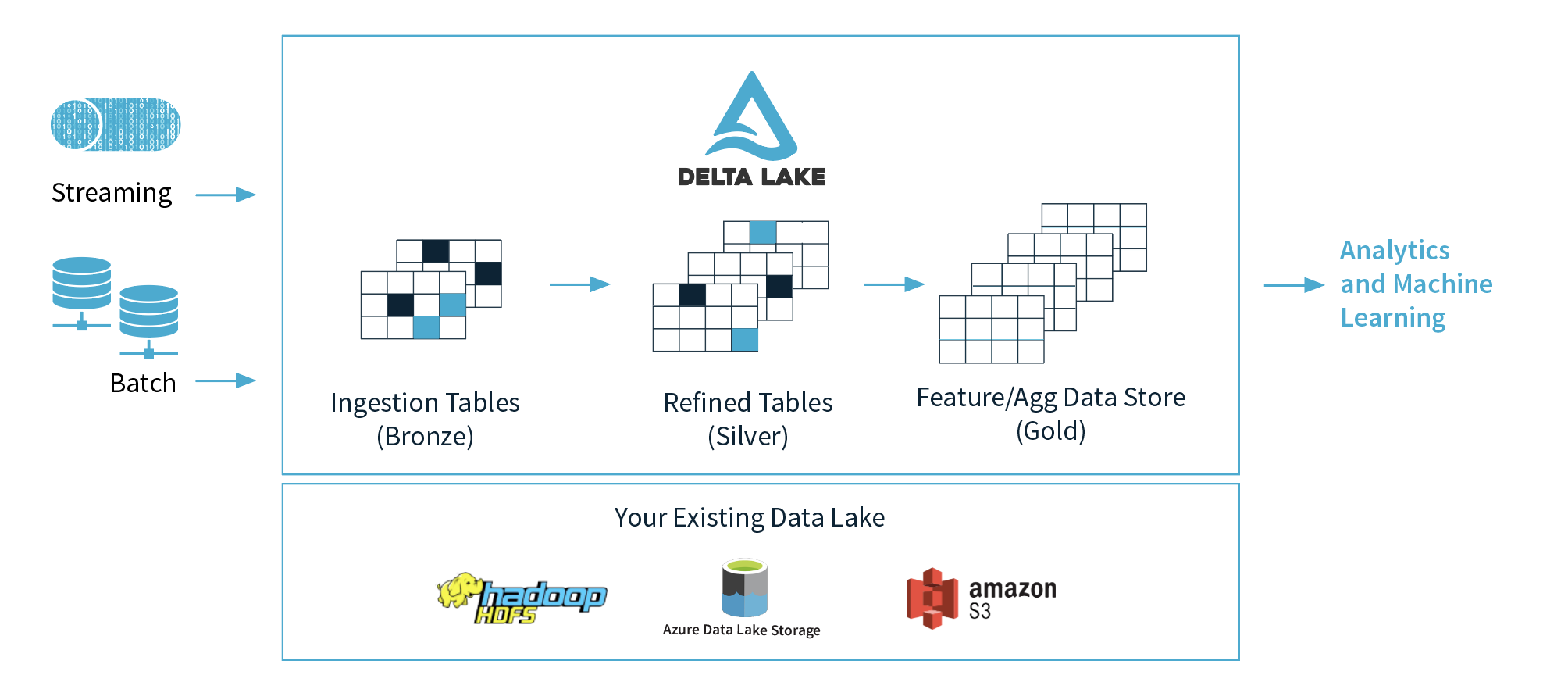
Delta Lake は Apache Spark の読み書きに ACID な transaction を提供するストレージレイヤーの OSS である。
Databricks が作り、2019年4月に v0.1.0 がリリースされたのが最初だ。
使い方はめちゃ簡単で、dependency を設定した上で Spark で
dataframe
.write
.format("delta")
.save("/data")
のように読み書きすればよい。
データレイク化が進むと多種多様なデータが一元的に管理され、それらデータに対して横断的なクエリを実行できるようになる。
各データの更新タイミングも様々であり、そのような状況では ACID 特性の中でも特に Isolation (独立性) が問題となってくる。
Spark を処理エンジンとして使う場合、データソース・読み方によっては isolation level が弱くなってしまうことがあるというのは過去のポストでも述べた。
おそらくこのことが Delta Lake の開発の強い動機となっているのではないだろうか。
Delta Lake は最も強い isolation level である “serializability” を提供する。
ACID transaction の他には schema に合わないデータを弾いたり過去のデータのスナップショットにアクセスしたりなどの機能がある。
どれもデータレイクの治安を守る方向であり、データスワンプ化に抵抗したいようだ。
これらを実現しているのが transaction log という仕組みとのこと。
Delta Lake は table に対する変更の transaction を atomic な commit という単位に分け、commit ごとに操作を JSON file に書き出していく。
JSON file には 000000.json, 000001.json のように連番が振られており、2つの application が同時に table を更新するような場合は各 application が次の番号の JSON file を作れるかどうかで衝突を制御している。
JSON file はずっと蓄積していくため再計算のコストが大きくなっていくが、その時点での table の完全な状態を parquet にした checkpoint file というものを時折出力するという、compaction のようなことも行われる。
(Delta Lake は parquet 形式のデータ保存を前提としている)
詳しくは Databricks の blog を参照。
Apache Hudi
Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing.
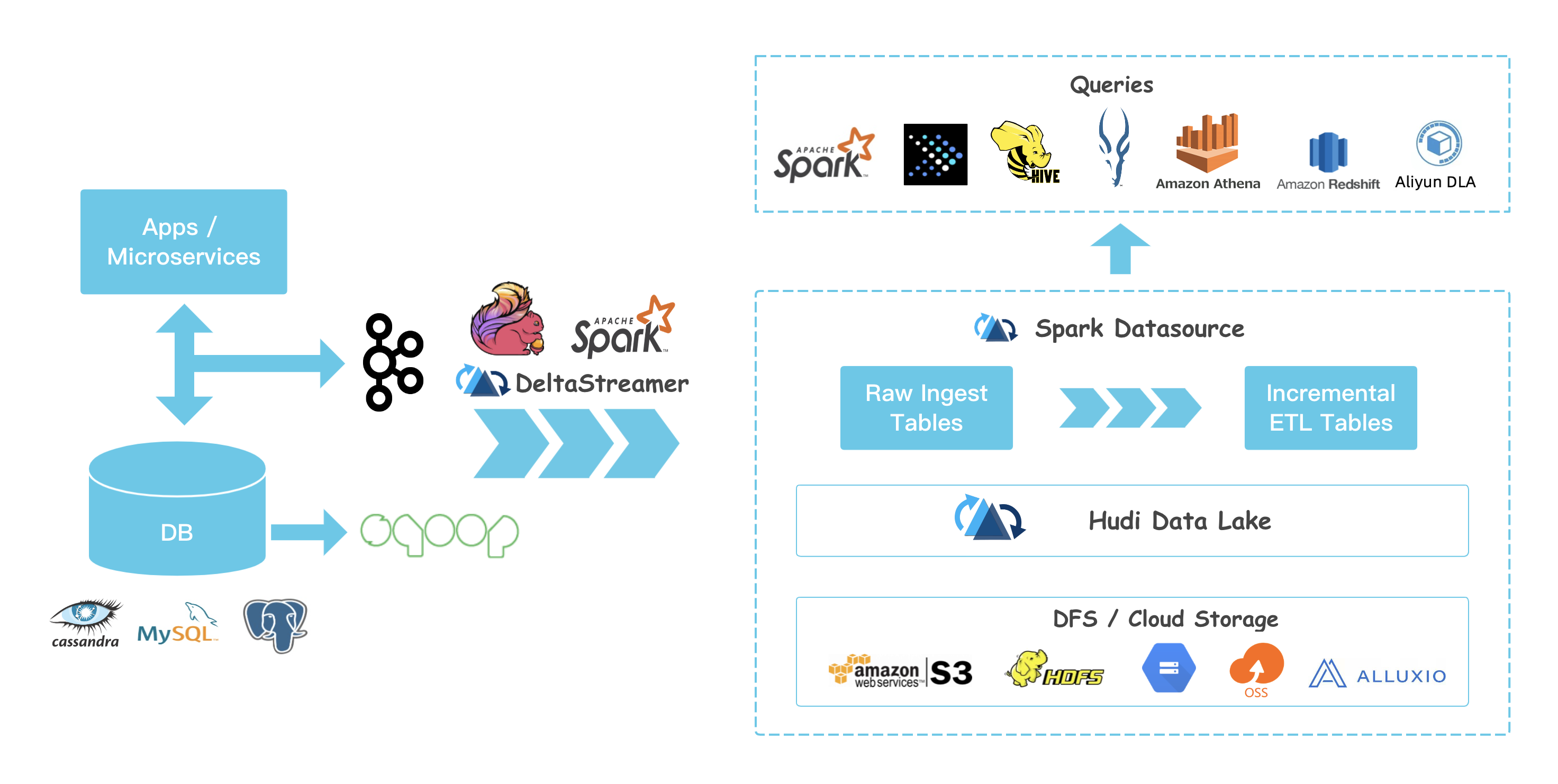
Apache Hudi で何ができるかを一言で説明するのは難しい。
簡単にまとめると HDFS や S3 等にある table にリアルタイムに近いデータ取り込みと、処理速度とデータの新鮮さのトレードオフに配慮した読み込みを提供する。
2016年から Uber が開発をしており、2020年に Apache Software Fundation の top-level project となった。
データレイクではあらゆる種類のデータを一元管理するが、その中には当然リアルタイム性の高いデータも含むことになる。
データレイク中のリアルタイム性の高いデータについては次のような要求が出てくる。
- table へのデータの取り込みはリアルタイムに近いスピードで細かくやりたい
- 分析クエリ等の table の読み込みにおけるクエリの速度は速くしたい (例えば列指向形式で保存されたデータの様に)
- 取り込まれたデータをすぐに読めるようにしたい
Hudi はこれに応えるものとなっている。
これらを実現するのが Merge On Read のデータ構造だ。
Hudi の table には Copy On Write と Merge On Read の2種類がある。
ここでは Hudi の肝である後者について触れておきたい。
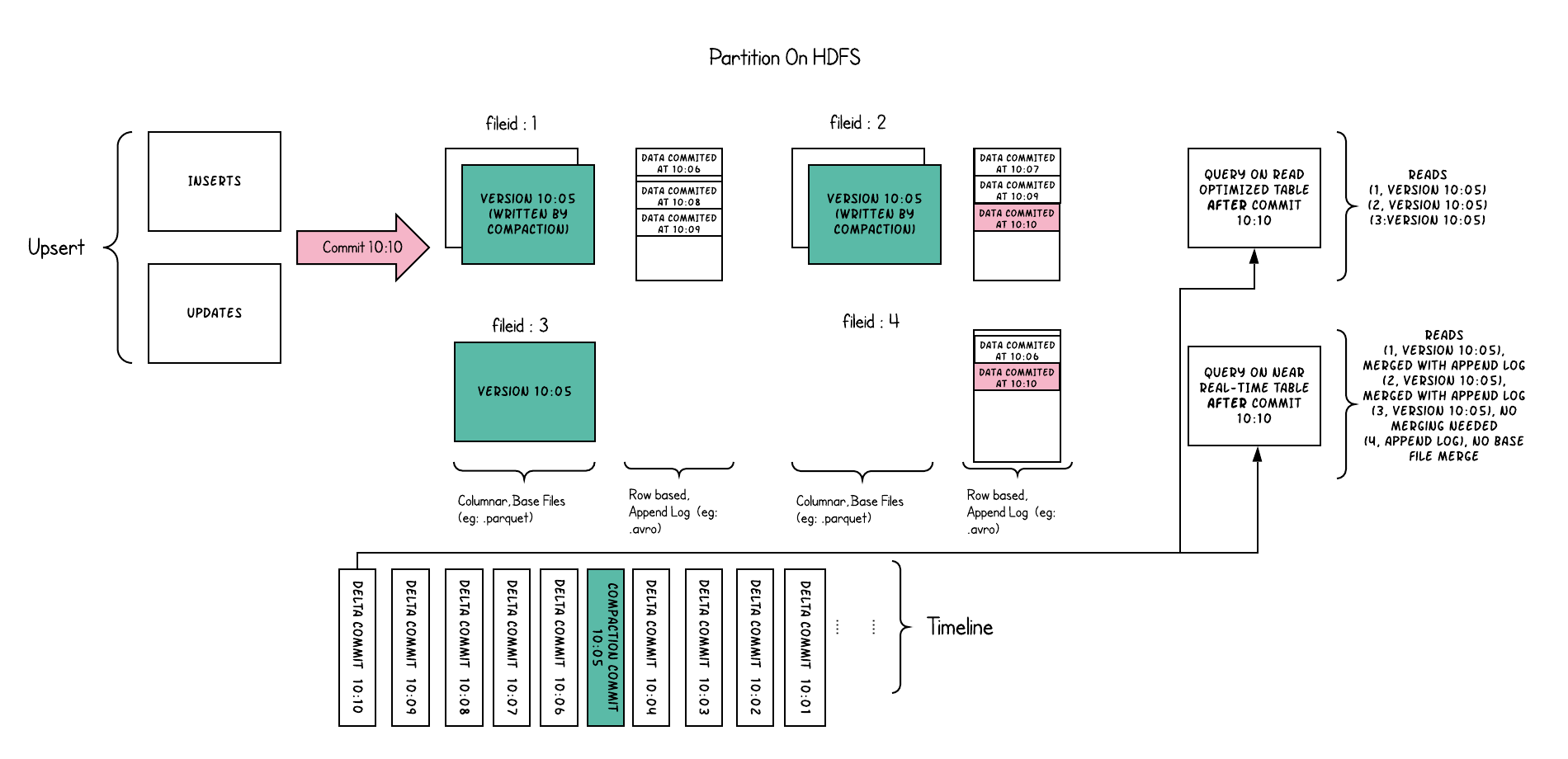
Apache Hudi Merge On Read TablePermalink
table に加えられた変更についての情報は timeline に追加される。
時系列になった変更についてのメタデータのようなものだろうか。
この timeline によって snapshot isolation が保証される。
最初にデータが追加されたときは parquet 等の列指向のフォーマットで保存される。
その一方でその後のデータの追加・更新については Avro 等の行指向のフォーマットの delta log に記載される。
ここがミソであり、列指向のフォーマットでは1レコードずつなどの細かい追加・更新が高コストになるのでその部分を行指向の delta log にまかせている。
追加・更新が増えてくると delta log がどんどん長くなってしまうので、あるタイミングで compaction を行って直近までの delta log の変更内容を反映した列指向ファイルを作成する。
これを読む方法は2通りある。
Snapshot Queries では読み取り時に列指向ファイルと行指向の delta log をどちらも読んで merge して最新の結果を返す。
(これが “Merge On Read” ということ)
一方で Read Optimized Queries では直近で compaction が行われた時点での列指向ファイルだけを読み、その時点の結果を返す。
つまりデータの新鮮さが重要な場合は Snapshot Queries, データの新鮮さよりもクエリの速度を優先したい場合は Read Optimized Queries が有利ということだ。
これらはトレードオフとなるので状況に応じて使いわけることになる。
2通りと述べたが実際はもう1つ、 Incremental Queries というものもある。
これはある時点からの差分のみを読み出して処理するというものとなっている。
event time と processing time の差があるものを DFS 上に書き出すのに適している。
ちなみに Merge On Read ではないもう1つの table type である Copy On Write は、Merge On Read の構造から delta log を消したものとなっている。
すなわち書き込み時に常に列指向ファイルの更新がおこり、新しく作り直される。(という意味で “Copy On Write”)
書き込みのたびに常に compaction が発生していると言ってもよい。
更新頻度が低いデータならこちらの table type を使うのが適しているだろう。
Hudi の table は Spark, Hive, Presto 等からクエリすることができる。
公式ドキュメント的には Spark 推しの感がある。
Apache Kudu
Apache Kudu is an open source distributed data storage engine that makes fast analytics on fast and changing data easy.
Apache Kudu はストリーム処理などの追加・更新の速いデータをすぐに分析できるようにすることを目的としている。
Cloudera 社の内部プロジェクトとして始まり、2016年から Apache Software Foundation の top-level project となった。
Kudu の目指すところは Hudi とよく似ているが、次の点で異なっている。
- Kudu は OLTP つまり小さなデータアクセスを大量にさばくのにも向いている
- Kudu は Hudi の incremental queries のようなことはできない
- Kudu は HDFS や S3 のような cloud storage 上にデータを持つのでははく、Raft の合意で制御された独自のサーバー群を要する
Kudu では各 table のデータが tablet という単位により構成される。
tablet はいわゆる partition によく似た概念となっており、key の範囲による分割、ハッシュ値による分割、またはその組み合わせにより分割される。
1つの tablet は複数の tablet server に replication されており、そのうちの1つが leader として振る舞い書き込みを受け付ける。
leader と follower の関係は Raft 合意アルゴリズム により管理される。
一方で master server では tablet のメタデータ等が管理されており、client はまず master と通信することになる。
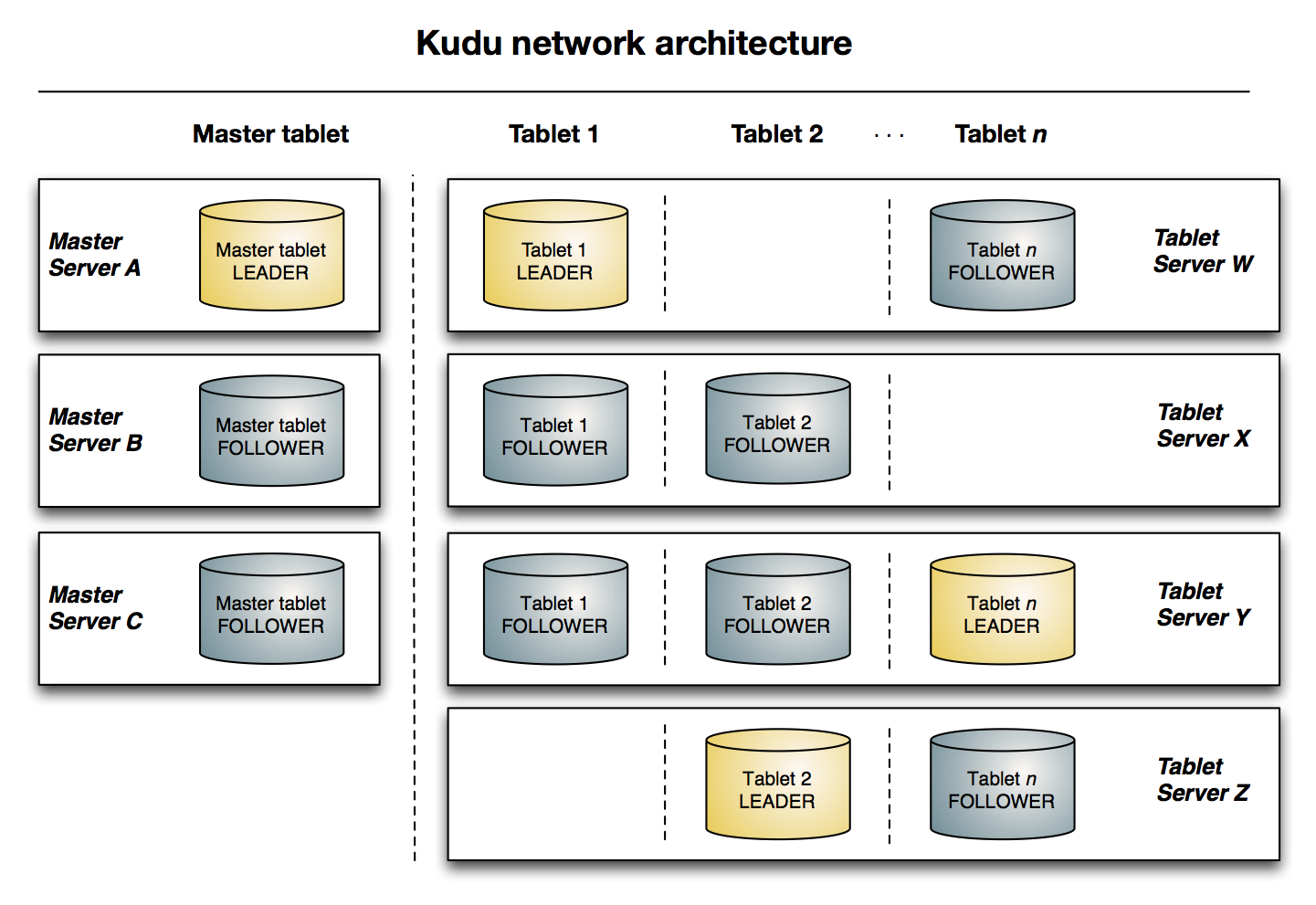
Apache Kudu Architectural Overview
読み書きに関する内部的な振る舞いについては Cloudera 社のブログ記事 (日本語訳) が参考になる。
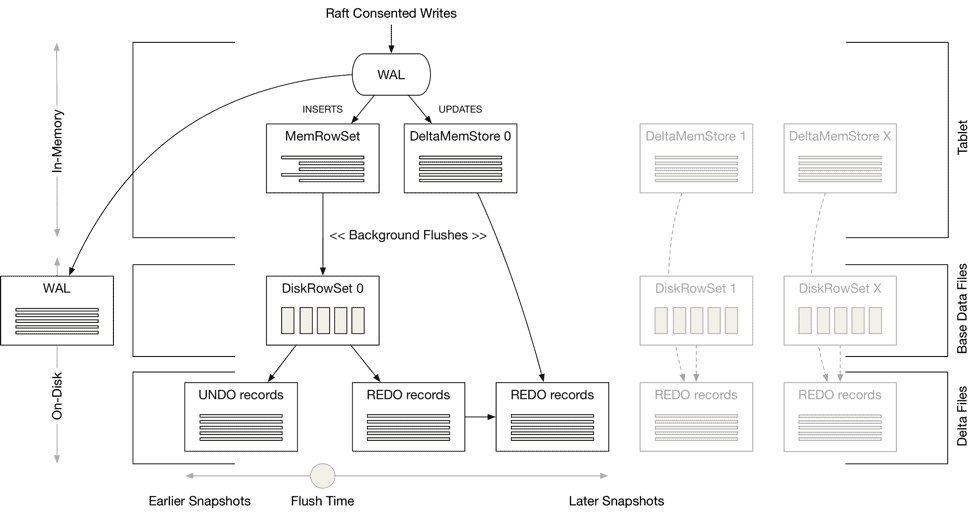
CLOUDERA Blog Apache Kudu Read & Write Paths
client 側からはおそらく見えないが、内部的には
- メモリ上の MemRowSet, DeltaMemStore
- 列指向の base data file
- 差分を表す delta file (UNDO/REDO records)
の3段の構成になっている。 (それと WAL も)
delta file を使うのは Hudi 等と同じだが一度メモリ上で変更を受けるという段があるのが特徴的だ。
挿入はある tablet のメモリ上の MemRowSet にまず追加される。
また任意の timestamp の snapshot を得るために、MemRowSet 上のデータへの更新・削除はの差分は REDO records へと保存される。
MemRowSet がいっぱいになると最新の状態が列指向の base data file へ書き出され、更新・削除前の状態は UNDO records へと書き出される。
読み取りのときは MemRowSet とディスク上の base data file + delta file をスキャンすることになる。
したがって delta file の数やサイズが大きくなると遅くなる。
やはりここでも compaction が必要となってくる。
このように memory を使うため server が必要であり、データレイクでよく言われるコンピューティングとストレージの分離が完全にはできない。
Cloudera 的と言えるかもしれない。
読み取りには2つのモードがある。
デフォルトは READ_LATEST であり、名前のとおり snapshot をとってすぐにデータを読むとのこと。READ_LATEST は比較的弱い read committed の isolation level を示す。
これはおそらく Raft や WAL を経て変更が可視になるまでに時間を要するためだ。
read committed は実用では問題が起こることもある。(ex. Spark クエリの分離レベル)
もう一つは READ_AT_SNAPSHOT であり、明示的 (推奨) または暗黙的に読み取る対象の timestamp を指定する。
書き込みの operation が完了し、その timestamp までの変更が安全に読めるようになるまで待って結果を返すことになる。
isolation level はおそらく最も強い serializable となっている。
したがって2つのモードはデータの新鮮さと isolation level (consistency も?) のトレードオフとなっている。
まとめ
Delta Lake, Apache Hudi, Apache Kudu の3つを見比べて見てとても面白いのは、課題感は少しずつ違っているのにどれも列指向ファイル + 差分ファイル (delta file) というアーキテクチャを中心に置いているということだ。
Delta Lake では transaction を重視している一方で Hudi ではリアルタイムデータをすぐに分析することを目指し、かつ Kudu ではさらに OLTP もサポートする。
おそらく導入は Delta Lake が最も簡単であり、Kudu に至っては server を用意する必要があるのでハードルが1段高い。
同じアーキテクチャということもあり、例えば time travel の機能などは共通して提供されている。
バランス的には Apache Hudi がよさそうだが、どれを使うべきかは work load 次第だろう。
hourly のデータ更新に慣れすぎていて fast data - fast analysis の需要に気づけないといこともよくありそう。