
書籍について
タイトルのとおりで RAG や AI エージェントについて書かれた本。
出版は2024年11月。
LangChain や LangGraph を使ったサンプルコードが豊富に載っている。
著者の方は3名ともジェネラティブエージェンツ社の方で、AI エージェントを扱う会社らしい。
前作として『ChatGPT/LangChainによるチャットシステム構築[実践]入門』という本もあり、本書の何章かは前作の内容を引き継いでアップデートしているとのこと。
個人的にはこれまで LLM や LangChain など追えていなかったので勉強になったし、自分でコードを写経して動かしてみるのがとても面白かった。
AI エージェントまわりの技術を実感したい人におすすめ。
ちなみにサンプルコードを動かすためには OpenAI をはじめとする様々なサービスに登録する必要があり、料金が発生するものも含まれている。
このポストについて
書籍「LangChainとLangGraphによるRAG・AIエージェント[実践]入門」を読んで、面白かったので内容をまとめる。
各章ごとに内容を挙げていってもいいのだが、ここではそうはせず、本書に登場する言葉や概念をまとめていくことにする。
ちなみにこの記事で紹介するプロンプト等は書籍そのままではなく、少し変更している。
実際のプロンプトを知りたい場合は書籍を読んでください。
プロンプトエンジニアリング
これは知っている人も多いだろう。
プロンプトとは主に自然言語で記述される、LLM に与える命令のこと。
LLM をアプリケーションに組み込む場合はプロンプトはテンプレート化し、入力データをそれに差し込む形となる。
LLM は必ずしも人間の出す命令に対して望ましい回答を出力してくれるわけではない。
望ましい回答を出力してもらえるよう、プロンプトを工夫するテクニックがプロンプトエンジニアリングである。
本書ではプロンプトエンジニアリングの具体的な手法として次の3つが紹介されていた。
ちなみにここで例として示している出力は実際に OpenAI の LLM gpt-4o-mini で出力したものである。
Zero-shot プロンプティング
簡単なタスクであれば、特に追加の情報がなくとも (=Zero-shot) 望ましい回答を得ることができる。
system: 次の日本酒のレビューをポジティブ・ネガティブ・中立のどれかに分類してください。
user: ふくよかで芳醇な香り
出力
ポジティブ
Few-shot プロンプティング
より複雑なタスクになった場合、デモンストレーションを与えることで回答の精度を高めることができる。
いくつかのデモンストレーションを示すため、Zero-shot ではなく Few-shot である。
system: 次の内容が日本酒についての話かどうかを判定してください。
user: ふくよかで芳醇な香り
assistant: True
user: 明日は雨らしい
assistant: False
user: AI エージェントはソフトウェア開発を変えるだろう
出力
False
回答の精度に加え、出力の形式も示すことができる。
Zero-shot Chain-of-Thought プロンプティング
system: 以下の計算の結果のみ出力してください。
user: たかし君が200円のリンゴを3個、100円のミカンを2個買ったら財布に150円残りました。たかし君は最初何円持っていたでしょう?
出力
たかし君は最初500円持っていました。
この例では回答が間違っている。(またはたかし君の万引きが発覚したか)
このように中間的な推論が必要な場合に有効なのが Zero-shot Chain-of-Thought プロンプティングである。
プロンプトを少し変えてみる。
system: 以下の計算の結果をステップバイステップで考えてください。
user: たかし君が200円のリンゴを3個、100円のミカンを2個買ったら財布に150円残りました。たかし君は最初何円持っていたでしょう?
出力
たかし君の最初の金額を求めるために、次のステップで計算を進めます。
1. **リンゴの合計金額を計算する**:
リンゴは1個200円で3個買ったので、
\[
200円 \times 3 = 600円
\]
2. **ミカンの合計金額を計算する**:
ミカンは1個100円で2個買ったので、
\[
100円 \times 2 = 200円
\]
3. **リンゴとミカンの合計金額を求める**:
リンゴとミカンの合計金額は、
\[
600円 + 200円 = 800円
\]
4. **財布に残っている金額を考慮する**:
たかし君は買い物をした後に150円残っているので、最初の金額を求めるために800円(使った金額)と150円(残っている金額)を足します。
\[
800円 + 150円 = 950円
\]
したがって、たかし君は最初に950円持っていたことになります。
見事正解した。
このように「ステップバイステップで考える」ことを示すだけで、回答が正確になるという有効な手法である。
プロンプトエンジニアリングには上に挙げた以外の手法もある。
詳しくは Prompt Engineering Guide | Prompt Engineering Guide などを参考にするとよい。
LangChain
LangChain の概要
LangChain とは LLM アプリケーションを開発するためのフレームワークである。
公式ドキュメントによると、
LangChain simplifies every stage of the LLM application lifecycle:
- Development: Build your applications using LangChain’s open-source components and third-party integrations. Use LangGraph to build stateful agents with first-class streaming and human-in-the-loop support.
- Productionization: Use LangSmith to inspect, monitor and evaluate your applications, so that you can continuously optimize and deploy with confidence.
- Deployment: Turn your LangGraph applications into production-ready APIs and Assistants with LangGraph Platform.
のように開発ライフサイクルの各ステージについての機能がある。
Productionization の LangSmith については後述するとして、ここでは主に Development について述べる。
ちなみに書籍では Deployment の部分についてはあまり触れられていなかった。
LangChain の構成
LangChain は Python や JavaScript のライブラリとして OSS で提供されている。
書籍では主に Python で紹介されていたので、ここでもそれにならう。
LangChain には次のようなパッケージが含まれる。
langchain-core- ベースとなる抽象化や LCEL (後述)
langchain-openaiやlangchain-anthropicなど- OpenAI や Anthropic などパートナーとのインテグレーション
langchain-community- パートナーのパッケージとして独立していない各種インテグレーション
langchain- LLM アプリケーション特定のユースケースに特化した機能
langchain-text-splitter- テキストの chunk への分割
langchain-experimental- 研究・実験目的のコードなど
コード例
実際にコードを見るとイメージしやすいというところで見てみよう。
ただしセットアップ方法などはこのポストでは省略。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# プロンプトを用意
prompt = ChatPromptTemplate.from_template(
"{drink}の原料を教えてください。"
)
# LLM を用意
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.0)
# parser を用意
output_parser = StrOutputParser()
# 用意したものをつなげて処理の連鎖を作成
chain = prompt | llm | output_parser
# 実行
result = chain.invoke({"drink": "日本酒"})
print(result)
出力
日本酒の主な原料は以下の4つです。
1. **米**: 日本酒の基本的な原料で、特に酒造りに適した「酒米」が使用されます。酒米は、一般的な食用米よりも大きく、デンプン含量が高いのが特徴です。
2. **水**: 日本酒の製造には大量の水が必要です。水の質は日本酒の味に大きく影響するため、清らかでミネラルバランスの良い水が求められます。
3. **酵母**: 発酵を促進するために使用される微生物で、アルコールと香りを生成します。日本酒専用の酵母が多く存在し、それぞれ異なる風味を引き出します。
4. **麹(こうじ)**: 米に麹菌を繁殖させたもので、デンプンを糖に変える役割を果たします。麹は日本酒の発酵過程において非常に重要な役割を担っています。
これらの原料を組み合わせて、発酵・熟成を経て日本酒が作られます。
このように LLM アプリケーションに必要な要素 (Runnable) を | でつなげて鎖のように記述する方法を LangChain Expression Language (LCEL) と言う。
関数型プログラミングっぽくなっており、プログラミングとしての型が提示されていてとてもいいと思った。
プロンプトはテンプレート化されているため、例えば日本酒をビールに変えて実行することもできる。
# 実行
result = chain.invoke({"drink": "ビール"})
print(result)
上記は非常に簡単な例だが、次のような複雑なこともできる。
詳しくは書籍を参照。
- Pydantic のモデルを出力形式として指定
RunnableLambdaで任意の関数を chain に差し込むRunnableParallelで並列処理RunnablePassthroughで処理をスルー- RAG の実装
- 発展型の Advanced RAG も含む
LangSmith
LangSmith とはプロダクショングレードの LLM アプリケーション構築のためのプラットフォーム。
LangChain の開発元、LangChain, Inc. により提供されている web サービスである。
以下の3つの機能がある。
- Observability: トレーシングなど
- Evals: LLM アプリケーションのオンライン/オフライン評価
- Prompt Engineering: プロンプト管理
ここでは3つのうちの Observability, Evals について述べる。
Observability
LangChain による LLM アプリケーションを実行すると、LangSmith にその情報が送られ、詳細分析ができるというのがこの機能。
トレーシングのためのセットアップを行っておく必要がある。
例えば前述の LCEL の例で示したコードの実行結果は次のように表示される。
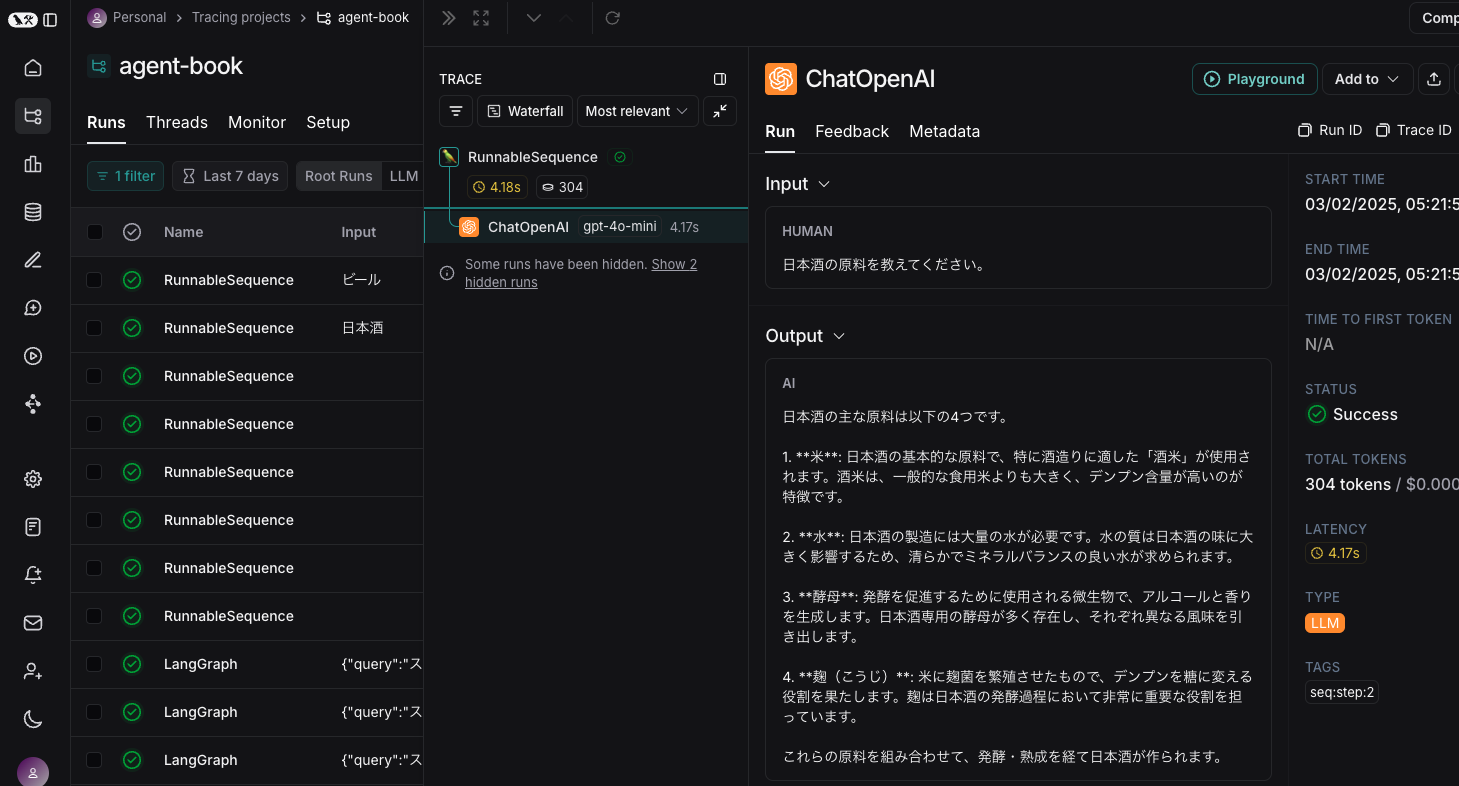
LLM への Input/Output が表示されている。
この簡単な例ではあまりありがたみがわからないかもしれない。
しかし後述するエージェントデザインパターンのような、複数の LLM への入出力を経て高度なタスクを実行するようなケースにおいては非常に強力なサポートになる。
これがないと各段階で LLM が何をやっているのかがわからない。(もしくは自分でロギングするか…これはこれでしんどい)
Evals
LangSmith を使って LLM アプリケーションのオフライン/オンライン評価を行うことができる。
ここではオフライン評価について見ていこう。
書籍では Ragas という LLM アプリケーションの評価のためのライブラリを利用した RAG の評価を行っている。
オフライン評価の流れは以下。
ちなみに書籍ではほとんどのコードは Google Colab で実行することになっている。
(開発環境などと読み替えてもいいだろう)
- Google Colab 上でデータセットを生成
- LangSmith にデータセットを登録
- Google Colab 上でオフライン評価を実施し、LangSmith に登録
「このデータセットに対する評価」というのが Experiment という単位で LangSmith 上で管理され、LLM アプリケーションの性能改善に伴うメトリクス (評価指標) の変化を追うことができるようになる。
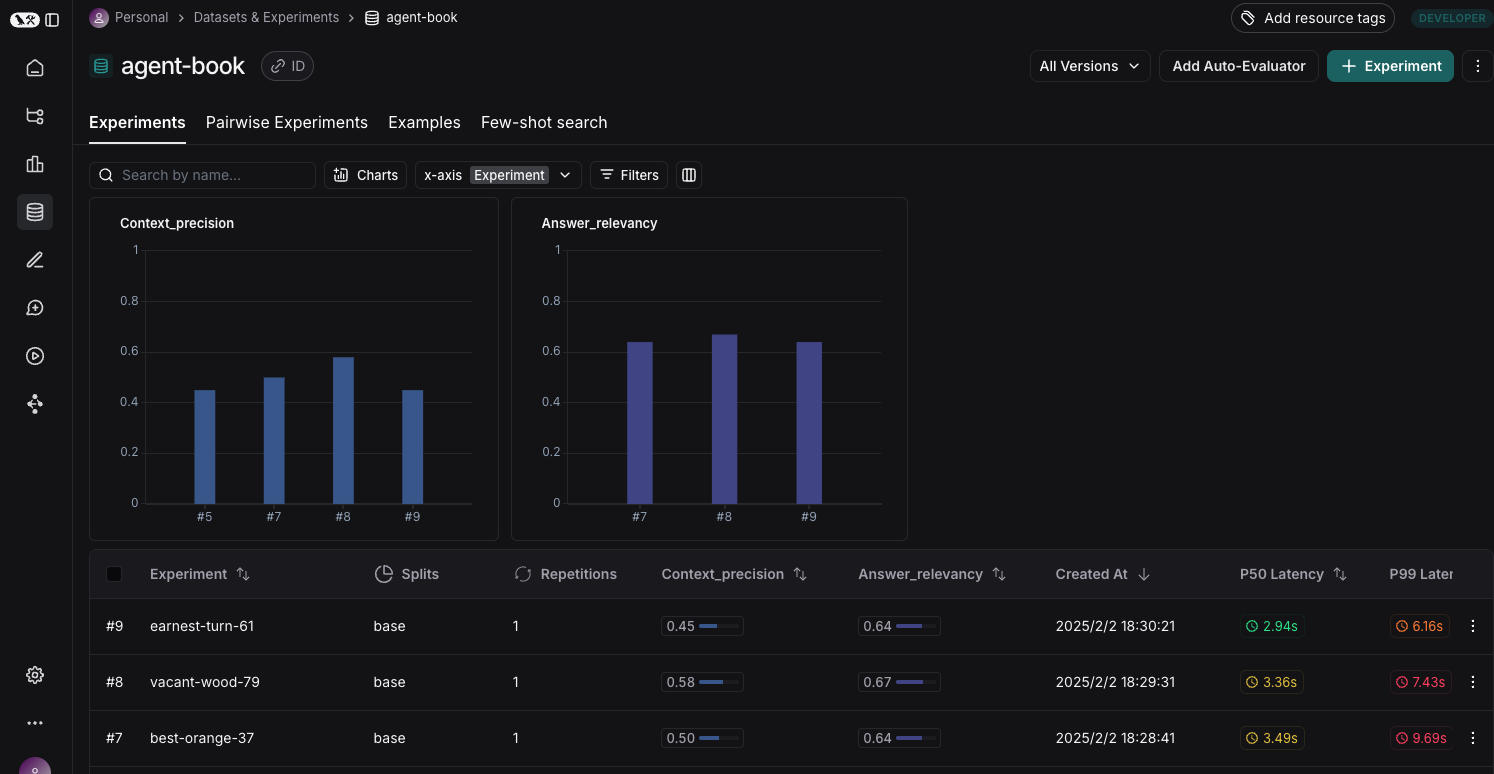
この例では context precision および answer relevancy というメトリクスを扱っている。
Ragas にはこの他にも様々なメトリクスがあるので、アプリケーションにあったものを選ぶ必要がある。
こちらのオフライン評価のコードはまあまあ複雑なので割愛。
書籍のほぼすべてのコードは写経して実行したが、このオフライン評価の部分だけはうまくいかなかったため、
を参考にして作成・実行した。
LLM アプリケーションのオフラインの性能評価の方法をまったく知らなかったので、個人的には新鮮だった。
評価データも LLM で作るのか、と。
AI エージェント
今、世間でも話題になっている AI エージェント。
AI エージェントの定義はいろいろありそうだが、本書では次のようになっている。
AIエージェントとは、複雑な目標を自律的に遂行できるAIシステムを指します。従来のAIシステムが特定のタスクに特化していたのに対し、LLMを活用したAIエージェントは、与えられた目標を達成するために必要な行動を自ら決定し、実行することができます。この自律性により、より汎用的で柔軟なLLMアプリの実現が可能になります。
いくつかの汎用 LLM エージェントのフレームワークが例として挙げられている。
書籍ではこれらのフレームワークについてそれぞれ軽い説明が記載されているが、このあたりからエージェントやばいなと思い始めた。
特にマルチエージェントのアプローチはほぼチームビルディングであり、マネジメントでは?
マルチエージェントの定義は次のように書かれていた。
- マルチステップなマルチエージェント:一連の処理の中で、複数のシステムプロンプトを使って、役割やステップごとに別々のAIエージェントで処理を行う、ワークフローの最適化を目的とした処理形態
- マルチロールなマルチエージェント:異なるペルソナや役割を持たせた複数のエージェントを、目的に向かって協調動作させる形態
マルチエージェントでソフトウェア開発を自動化するためのフレームワークも紹介されていた。
Devin などは今すごく話題になっており、これらのエージェントで今後ソフトウェア開発は変わってくんだろうなと思っている。
LangGraph
LangGraph とは LLM を活用した複雑なワークフローを開発するためのライブラリである。
ワークフローといえば Apache Airflow だが、あの DAG のようなものをイメージすればよい。
(ただし cyclic であることは許されているので DAG ではない)
DAG の task にあたるところで LLM の呼び出しがあるようなイメージ。
例えば書籍ではサンプルとして要件定義書生成 AI エージェントの例が記載されている。
このエージェントは雑に「◯◯のようなアプリを作りたい」と言うと要件定義書を作成してくれるといったもの。
ワークフローは次のようになっている。
flowchart TD
S@{ shape: circle, label: "Start" }
generate_personas["`generate_personas
ペルソナを生成`"]
conduct_intervies["`conduct_intervies
生成したペルソナにインタビュー`"]
evaluate_information["`evaluate_information
インタビュー結果を評価`"]
generate_requirements["`generate_requirements
要件定義書を作成`"]
E@{ shape: circle, label: "End" }
S --> generate_personas
generate_personas --> conduct_intervies
conduct_intervies --> evaluate_information
evaluate_information --> generate_requirements
evaluate_information -- 情報量が不十分な場合 --> generate_personas
generate_requirements --> E
内部的にアプリのユーザーを想定したペルソナを作成し (generate_personas)、それに対してインタビューを行う (conduct_intervies)。
そのインタビューの結果を評価し (evaluate_information)、情報が十分なら要件定義書を作成して (generate_requirements) 終了する。
情報が不十分ならペルソナを追加で作成する。
LangGraph は名前のとおりこのグラフ構造を表現するものとなっている。
グラフのノード間のデータの引き渡しには state という概念があり、まずこれを定義してやる必要がある。
class InterviewState(BaseModel):
user_request: str = Field(..., description="ユーザーからのリクエスト")
personas: Annotated[list[Persona], operator.add] = Field(
default_factory=list, description="生成されたペルソナのリスト"
)
...
各ノードの処理も実装しておく。
ノード内の処理は LangChain で書くことができる。
class PersonaGenerator:
def __init__(self, llm: ChatOpenAI, k: int = 5):
self.llm = llm.with_structured_output(Personas)
self.k = k
def run(self, user_request: str) -> Personas:
prompt = ChatPromptTemplate.from_messages(
# ペルソナ作成用のプロンプト
...
)
chain = prompt | self.llm
# ペルソナを生成
return chain.invoke({"user_request": user_request})
...
各ノードの処理が実装できたらワークフローを構築する。
class DocumentationAgent:
def __init__(self, llm: ChatOpenAI, k: Optional[int] = None):
# 各種ジェネレータの初期化
self.persona_generator = PersonaGenerator(llm=llm, k=k)
...
# グラフの作成
self.graph = self._create_graph()
def _create_graph(self) -> StateGraph:
# グラフの初期化
workflow = StateGraph(InterviewState)
# 各ノードの追加
workflow.add_node("generate_personas", self._generate_personas)
...
# エントリーポイントの設定
workflow.set_entry_point("generate_personas")
# ノード間のエッジの追加
workflow.add_edge("generate_personas", "conduct_interviews")
workflow.add_edge("conduct_interviews", "evaluate_information")
# 条件付きエッジの追加
workflow.add_conditional_edges(
"evaluate_information",
lambda state: not state.is_information_sufficient and state.iteration < 5,
{True: "generate_personas", False: "generate_requirements"},
)
workflow.add_edge("generate_requirements", END)
# グラフのコンパイル
return workflow.compile()
def _generate_personas(self, state: InterviewState) -> dict[str, Any]:
# ペルソナの生成
new_personas: Personas = self.persona_generator.run(state.user_request)
return {
"personas": new_personas.personas,
"iteration": state.iteration + 1,
}
...
def run(self, user_request: str) -> str:
# 初期状態の設定
initial_state = InterviewState(user_request=user_request)
# グラフの実行
final_state = self.graph.invoke(initial_state)
# 最終的な要件定義書の取得
return final_state["requirements_doc"]
コードはかなり端折ったが、エッセンスはわかっていただけたと思う。
最後の run() を実行すれば要件定義書が作成される。
これを写経して実際に動かしてみたところ、それっぽい要件定義書ができて感動した。
LangGraph でちょっとしたコードを書けばこのような高度?なワークフローが実行できるのである。
内部的にはペルソナ作ってインタビューしてってやっているが、外部のユーザーからはそれはわからないようになっている。
逆に言うとこの程度の複雑さのワークフローになってくると LangSmith のトレーシングがかなり意味を持つようになってくる。
エージェントデザインパターン
ソフトウェア設計の言葉で「デザインパターン」というものがある。
これは設計でよくある問題を解決するための設計思想やアプローチを示すもの。
エージェントデザインパターンはこれの AI エージェント版のようなものであり、AI エージェントの設計のパターンを示す。
Yue Liu らによって提案された。
全 18 のパターンが紹介されている。
- 目標設定と計画設定
- Passive Goal Creator
- Proactive Goal Creator
- Prompt/Response Optimizer
- Single-path Plan Generator
- Multi-path Plan Generator
- One-shot Model Querying
- Incremental Model Querying
- 推論の確実性向上
- Retrieval-Augmented Generation (RAG)
- Self-Reflection
- Cross-Reflection
- Human-Reflection
- Agent Evaluator
- エージェント間の協調
- Voting-based Cooperation
- Role-based Cooperation
- Debate-based Cooperation
- 入出力制御
- Multimodal Guardrails
- Tool/Agent Registry
- Agent Adapter
書籍ではこのうちのいくつかについてのサンプルコードを示している。
ここでは簡単なところで Passive Goal Creator の例を見てみる。
Passive Goal Creator はユーザーの入力から具体的な目標を生成するパターンであり、この結果が後続の LLM への入力となる。
例えば次のようなプロンプトを用いて、目標を具体化する。
ユーザーの入力を分析し、明確で実行可能な目標を生成してください。
要件:
1. 目標は具体的かつ明確であり、実行可能なレベルで詳細化されている必要があります。
2. ...
ユーザーの入力: {query}
これを LLM に食わせてより具体的な目標を得、それにより後続の LLM が仕事をしやすくなるわけである。
サンプルコードでは様々なパターンを追加して組み合わせていくような例が示されており、LLM アプリケーションが賢くなっていく様を見て取ることができた。
体感として Self-Reflection, Cross-Reflection はなかなか有効だと感じた。
所感
個人的に LLM まわりをあまり追えていなかったこともあり、冒頭に述べたとおりだがとても興味深く、面白く読むことができた。
とはいえ挙げられていたライブラリなども含め、この分野は日進月歩で発展しているのでここで得た知識が陳腐化するのも早いだろう。
以下は細かい所感。
- テストが難しそう
- 必要な情報を渡せていないのか?LLM の性能の問題なのか?の見分けが難しい
- LangGraph のノード単位でコードを分割して手厚く単体テストしたり、LangSmith で調べたりなどで頑張るのだろうか
- 独特の不気味さ
- LangChain のプログラムとしての美しさ、その一方での LLM という得体の知れないもの
- この2つが組み合わさっていることに何とも言えない不気味さを感じる
- こんな簡単なプログラミングで抽象度の高い問題が解ける
- という感動
- 何かいろんなことができそうな気がする、しらんけど
- LLM アプリケーションはほぼマネジメントでは?
- agent design pattern とかマルチエージェントとか
ここで得た知識を業務に適用することを画策中。
面白いことができたらまた記事にするかも。