はじめに
Apache Spark 3.0.0 がリリースされました。
release note を見て個人的に気になったところなど簡単に調べました。
書いてみると Databricks の記事へのリンクばっかになってしまった…
全体感
こちらの記事を読めば全体感は OK.
公式の release note には
Python is now the most widely used language on Spark.
とあってそうなん?ってなったけど、こちらの記事だと
Python is now the most widely used language on Spark and, consequently, was a key focus area of Spark 3.0 development. 68% of notebook commands on Databricks are in Python.
と書いてありどうやら Databricks の notebook の話らしく、だったらまあそうかなという感じ。
プロダクトコードへの実装というよりは、アドホック分析や検証用途の話なんでしょう。
[Project Hydrogen] Accelerator-aware Scheduler
Spark 上で deep learning できるようにすることを目指す Project Hydrogen、その3つの大きな目標のうちの一つ。
YARN や Kubernetes では GPU や FPGA を扱えるようになっているので Spark でも扱えるようにしたいというモチベーション。
Spark のドキュメント によると
For example, the user wants to request 2 GPUs for each executor. The user can just specify
spark.executor.resource.gpu.amount=2and Spark will handle requestingyarn.io/gpuresource type from YARN.
のようにして executor に GPU リソースを要求できるみたいです。
Adaptive Query Execution
平たく言うと実行時に得られる統計情報を使って plan を最適化すると、静的に生成された plan より効率化できるよねという話。spark.sql.adaptive.enabled=true にすることで有効になります。
処理の途中で中間生成物が materialize されるタイミングで、その時点の統計情報を使って残りの処理を最適化する、というのを繰り返します。
Spark 3.0.0 では以下3つの AQE が実装されました。
- Coalescing Post Shuffle Partitions
- Converting sort-merge join to broadcast join
- Optimizing Skew Join
Spark 2 以前だとこのあたりは実行しつつチューニングするような運用になりがちでした。
特に skew の解消は salt を追加したりなど面倒だったりします。
これらが自動で最適化されるというのは運用上うれしいところ。
急なデータ傾向の変化に対しても自動で最適化して対応できるという面があります。
AQE に関してもやはり Databricks の解説記事がわかりやすいです。
図もいい感じ。
Dynamic Partition Pruning
こちらも AQE 同様にクエリのパフォーマンスを改善する目的で導入されたもの。
改善幅は AQE より大きいようです。
やはり実行時の情報を使って partition pruning を行い、不要な partition の参照を減らすという方法。
主に star schema における join 時のように、静的には partition pruning が行えない場合を想定しています。
比較的小さいことが多いと思われる dimension table 側を broadcast する broadcast join において、broadcast された情報を fact table の partition pruning に利用するというやり口。
Structured Streaming UI
“Structured Streaming” というタブが UI に追加された件。
Spark のドキュメントに例があります。
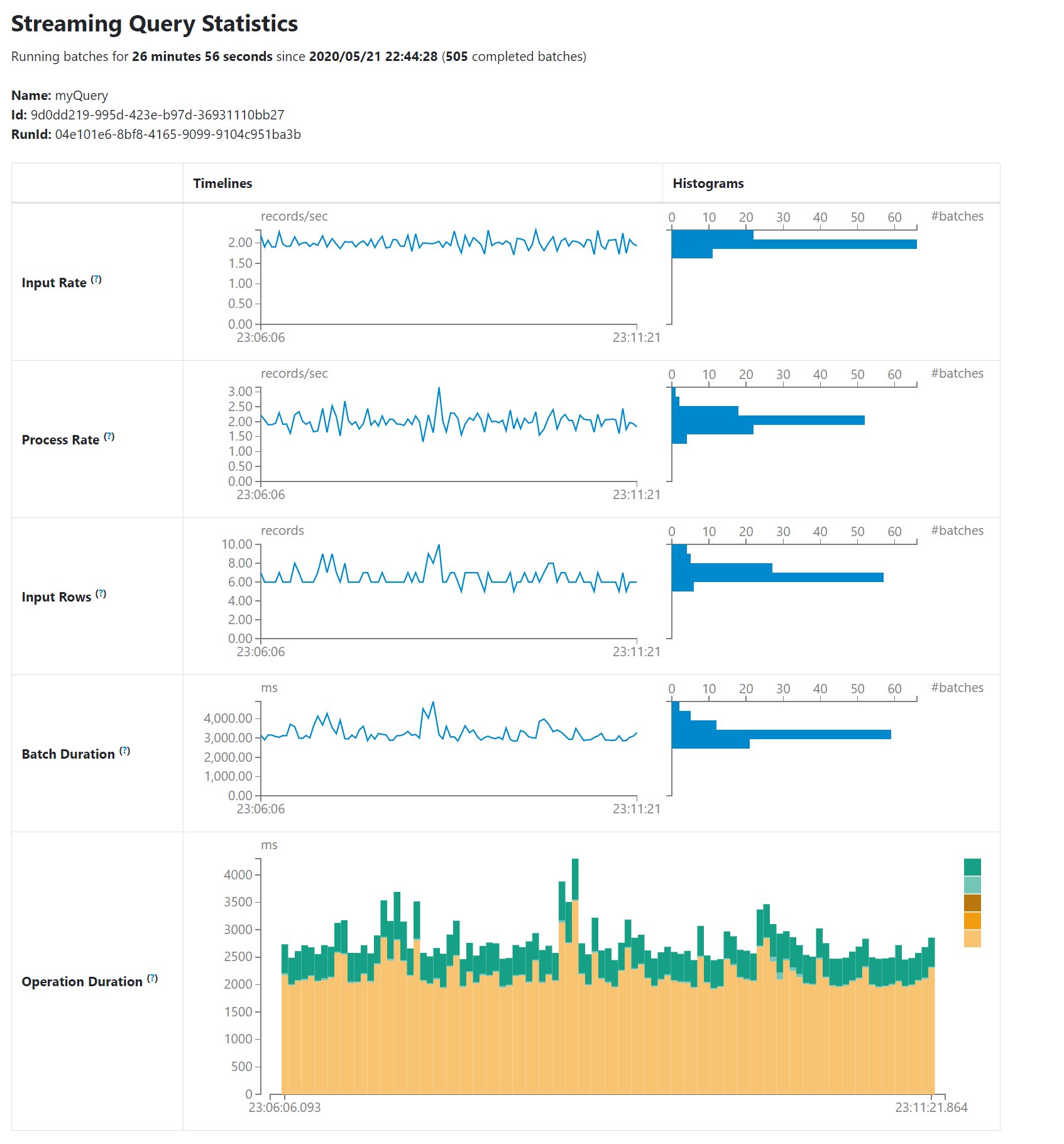
Spark 2.4 系では Structured Streaming を動かしていてもせいぜい job や stage が増えていくという味気ないものしか見えませんでした。
Spark 3.0.0 で実際に動かしてみたけど欲しかったやつ!という感じ。
ストリーム処理では入力データ量の変化の可視化がマストだと思ってます。
Catalog plugin API
これまでは CTAS (Create Table As Select) の操作はあったが、外部のデータソースに対して DDL 的な操作をする API が足りていませんでした。
CTAS も挙動に実装依存の曖昧さがありました。
そこで create, alter, load, drop 等のテーブル操作をできるようにしたという話。
ドキュメントの DDL Statements のあたりを読め何ができるかわかります。
以前のバージョンでも一部のデータソースについてはできた模様 (ex. Hive)。
今の自分の業務では Spark から DDL を扱うようなことはしないのでそれほど恩恵は感じられません。
notebook からアドホックな Spark のバッチを動かすというような使い方をしていればうれしいかもしれません。
Add an API that allows a user to define and observe arbitrary metrics on batch and streaming queries
クエリの途中の段階で何らかの metrics を仕込んでおいて callback 的にその metrics にアクセスできる仕組み。
Dataset#observe() の API ドキュメント を読むのが一番早いです。
この例ではストリーム処理を扱っているが、バッチ処理の例を自分で書いて試してみました。
// Register listener
spark
.listenerManager
.register(new QueryExecutionListener {
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
val num = qe.observedMetrics
.get("my_metrics")
.map(_.getAs[Long]("num"))
.getOrElse(-100.0)
println(s"num of data: $num")
}
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {}
})
// Make DataFrame
val df = Seq
.range(0, 1000)
.map((_, Seq("a", "b", "c")(Random.nextInt(3)), math.random()))
.toDF("id", "type", "value")
// Observe and process
val dfResult = df
.observe("my_metrics", count($"*").as("num"))
.groupBy($"type")
.agg(avg($"value").as("avg_value"))
// Run
dfResult.show
これを動かしたときの出力は次のようになりました。
+----+------------------+
|type| avg_value|
+----+------------------+
| c|0.5129435063033314|
| b|0.4693004460694317|
| a|0.4912087482418599|
+----+------------------+
num of data: 1000
observe() はその出力の DataFrame に対して schema やデータの中身を変更することはありません。
metrics を仕込むのみ。
logical plan を出力してみると observe() を入れることにより途中に CollectMetrics という plan が挿入されていました。
ソースを見ると accumulator を使っている模様。
なので observe() の集計のみで一度 job が動くわけではなく、クエリが2回走るという感じではありません。
全体の処理の中でひっそりと accumulator で脇で集計しておくといった趣でしょうか。
これは結構有用だと思います。
例えば何らかの集計をやるにしてもその最初や途中で、例えば入力データは何件あったか?みたいなことをログに出しておきたいことがあります。
というか accumulator で頑張ってそういうものを作ったことがある…
これがフレームワーク側でサポートされるのはうれしいです。
まとめ
2つのダイナミックな最適化に期待大。
気が向いたら追加でまた調べるかもしれません。