
Apache Iceberg の table を near real time に、つまり高頻度で更新するということをやってみた。
Apache Iceberg とは
Apache Iceberg (以下 Iceberg) は分散ファイルシステムやクラウドストレージ上の table format であり、Apache Hudi や Delta Lake と並んで data lake や lakehouse architecture で用いられる。
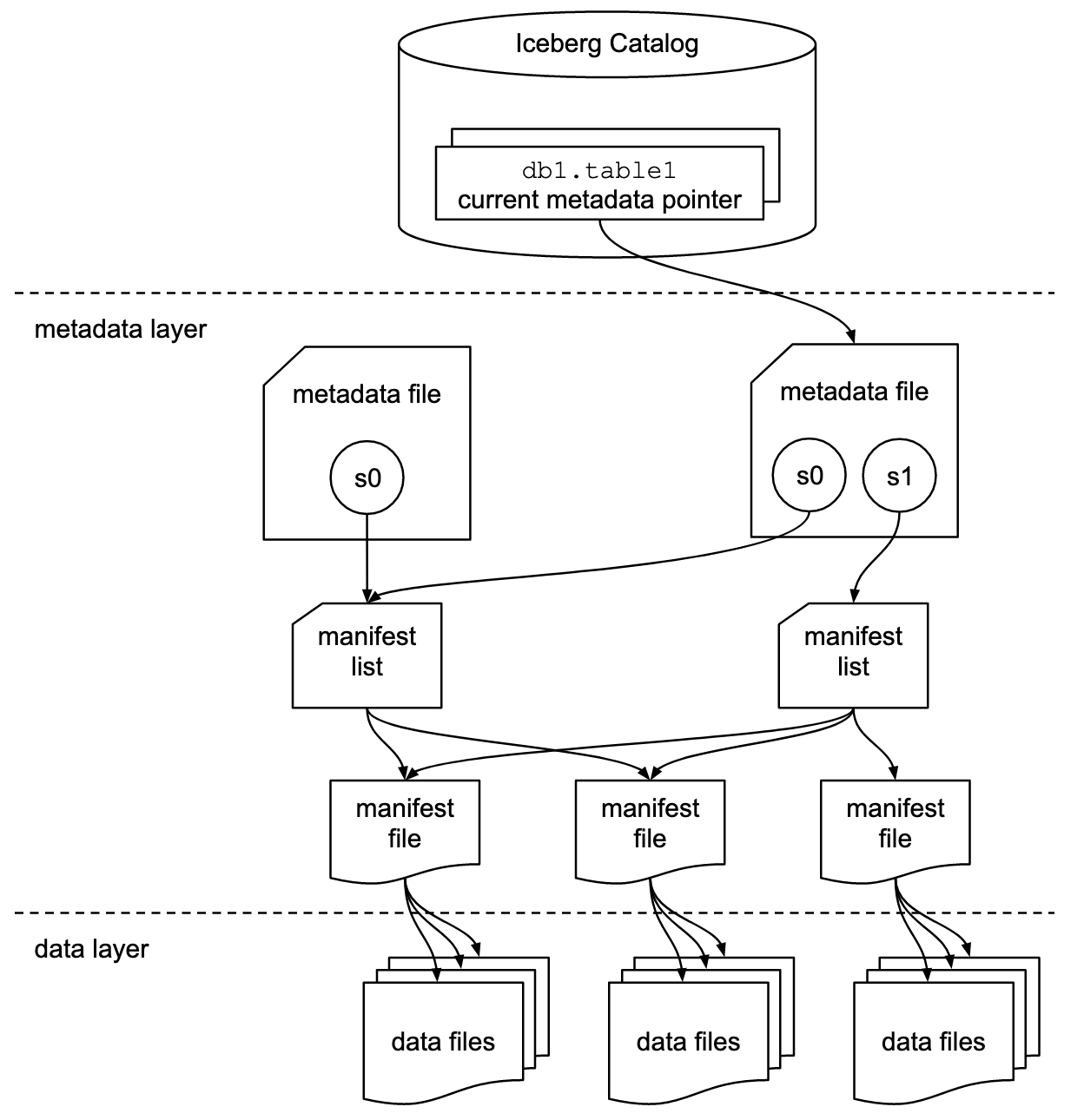
特徴的なのは table とデータ実体 (Parquet, Avro など) の間に metadata file, manifest list, manifest file の抽象的なレイヤーがあり、ファイル単位で table の状態を track できること。
これにより強い isolation level、パフォーマンス、schema evolution など様々な機能・性能を実現できるようになっている。
Apache Iceberg Iceberg Table Spec
詳しくは公式ドキュメントを参照のこと。
最近では SmartNews 社が Iceberg で data lake を構築したことを記事にしていた。
ベンダー提供の DWH 中心ではなく Lakehouse Architecture を目指すのであれば最有力の table format の1つだと言えそう。
このポストでやりたいこと
このポストでは Iceberg の table を near real time 更新することを想定して実験を行う。
多数の IoT デバイスで測定された温度情報が逐次的に送られていることを想定し、定期的にそれをデバイス ID ごとの最新の温度情報を持つ table へと書き出すものとする。
次のような要件を仮定する。
- 低レイテンシが要求されており、near real time での table 更新を行う
- 次のような schema のレコードが IoT デバイスから送信され得られる状態になっているものとする
device_id: デバイスに対して一意に振られている IDoperation: upsert or delete (後述)temperature: 測定された温度の値ts: 測定時の timestamp
- IoT デバイスは登録削除されることがあり、その場合は table 上の当該デバイス ID のレコードを削除する
- 削除の場合は
operation = 'delete'となっている。それ以外は'upsert'
- 削除の場合は
- 送られてくるレコードは timestamp (
ts) の順になっているとは限らない (out of order)
リアルタイム処理のフレームワークとしては Spark Structured Streaming を使用するものとする。
table 更新の実装
上記実験のための実装を行った。
各言語・フレームワーク等は以下のバージョンを使っている。
- Scala 2.13.10
- Java 11
- Spark 3.3.2
- Iceberg 1.2.1
実行可能な sbt project の全体を GitHub repository soonraah/streaming_iceberg に置いているのでご参考まで。
実装の主要な部分を次に示す。
// Create SparkSession instance
val spark = SparkSession
.builder()
.appName("StreamingIcebergExperiment")
.master("local[2]")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.my_catalog.type", "hadoop")
.config("spark.sql.catalog.my_catalog.warehouse", "data/warehouse")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
// Drop table
spark
.sql(
"""drop table if exists
| my_catalog.my_db.device_temperature
|""".stripMargin
)
// Create table
spark
.sql(
"""create table
| my_catalog.my_db.device_temperature
|(
| device_id int,
| operation string,
| temperature double,
| ts timestamp
|)
|using iceberg
|tblproperties (
| 'format-version' = '2',
| 'write.delete.mode' = 'merge-on-read',
| 'write.update.mode' = 'merge-on-read',
| 'write.merge.mode' = 'merge-on-read'
|)
|""".stripMargin
)
val random = new Random()
val addOutOfOrderness = udf {
(timestamp: Timestamp) =>
// add time randomly in [-5, +5) sec
val ms = timestamp.getTime + random.nextInt(10000) - 5000
new Timestamp(ms)
}
// Prepare input data
val dfInput = spark
.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
.select(
// Generate device_id in 0~127 randomly
(rand() * 128).cast(IntegerType).as("device_id"),
// 90% of operation is upsert and 10% is delete
when(rand() > 0.1, "upsert").otherwise("delete").as("operation"),
// Generate temperature randomly based on standard normal distribution
(randn() * 5.0 + 20.0).as("temperature"),
// timestamp is out of order
addOutOfOrderness($"timestamp").as("ts")
)
// Update table for each mini batch
dfInput
.writeStream
.trigger(Trigger.ProcessingTime(30.seconds))
.foreachBatch {
(dfBatch: DataFrame, batchId: Long) =>
println(s"Processing batchId=$batchId")
// Eliminate duplicated device_id
val dfDedup = dfBatch
.withColumn(
"row_num",
row_number()
.over(Window.partitionBy($"device_id").orderBy($"ts".desc))
)
.where($"row_num" === 1)
.drop($"row_num")
// createOrReplaceTempView() doesn't work
dfDedup.createOrReplaceGlobalTempView("input")
// Insert, update and delete records by 'merge into'
spark
.sql(
"""merge into
| my_catalog.my_db.device_temperature
|using(
| select
| *
| from
| global_temp.input
|) as input
|on
| device_temperature.device_id = input.device_id
| and device_temperature.ts < input.ts
|when matched and input.operation = 'upsert' then update set *
|when matched and input.operation = 'delete' then delete
|when not matched then insert *
|""".stripMargin
)
()
}
.start
.awaitTermination()
spark.stop()
この中の各処理を以下で説明していく。
// Create SparkSession instance
val spark = SparkSession
.builder()
.appName("StreamingIcebergExperiment")
.master("local[2]")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.my_catalog.type", "hadoop")
.config("spark.sql.catalog.my_catalog.warehouse", "data/warehouse")
.getOrCreate()
Spark から Iceberg を使うためには extensions の設定、および catalog の設定が必要となる。
これらは設定ファイルやコマンドラインからも指定できるが、今回は実験のためソースコード上で簡易に設定した。
// Create table
spark
.sql(
"""create table
| my_catalog.my_db.device_temperature
|(
| device_id int,
| operation string,
| temperature double,
| ts timestamp
|)
|using iceberg
|tblproperties (
| 'format-version' = '2',
| 'write.delete.mode' = 'merge-on-read',
| 'write.update.mode' = 'merge-on-read',
| 'write.merge.mode' = 'merge-on-read'
|)
|""".stripMargin
)
table 作成のクエリを実行している。
頻度の高い更新・削除を想定しているため、ここでは各操作に対して copy-on-write ではなく merge-on-read を指定している。
これにより書き込み時にデータファイル全体をコピーするのではなく、差分のみ追加するという形となり書き込みのコストが小さくなる。merge-on-read は format version 2 でしか指定できないため、その設定もしている。
// Prepare input data
val dfInput = spark
.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
.select(
// Generate device_id in 0~127 randomly
(rand() * 128).cast(IntegerType).as("device_id"),
// 90% of operation is upsert and 10% is delete
when(rand() > 0.1, "upsert").otherwise("delete").as("operation"),
// Generate temperature randomly based on standard normal distribution
(randn() * 5.0 + 20.0).as("temperature"),
// timestamp is out of order
addOutOfOrderness($"timestamp").as("ts")
)
ここでは IoT デバイスから送信されたとするストリームデータを作成している。
まずは .readStream.foramt("rate") によりストリームを発生させ、select() の部分で想定する schema にして値を入れている。
詳細はコメントを参照。
1点だけ補足すると、addOutOfOrderness() の部分では timestamp に対してわざと±5秒以内のランダムなゆらぎを与えおり、レコードが timestamp どおりに流れてこない状況を作っている。
dfInput
.writeStream
.trigger(Trigger.ProcessingTime(30.seconds))
.foreachBatch {
...
}
.start
.awaitTermination()
ストリームデータは foreachBatch により、30秒ごとの mini batch の単位で処理される。
この mini batch の中で table 更新を行う。
// Eliminate duplicated device_id
val dfDedup = dfBatch
.withColumn(
"row_num",
row_number()
.over(Window.partitionBy($"device_id").orderBy($"ts".desc))
)
.where($"row_num" === 1)
.drop($"row_num")
Iceberg の merge into (後述) では更新をかける側の table において結合のキーとなる column の重複は許されず、重複があった場合は次のようなエラーになってしまう。
org.apache.spark.SparkException: The ON search condition of the MERGE statement matched a single row from the target table with multiple rows of the source table. This could result in the target row being operated on more than once with an update or delete operation and is not allowed.
これを避けるため結合のキーとなる device_id ごとに一意となるよう、最新の行だけ残して重複を排除している。
// Insert, update and delete records by 'merge into'
spark
.sql(
"""merge into
| my_catalog.my_db.device_temperature
|using(
| select
| *
| from
| global_temp.input
|) as input
|on
| device_temperature.device_id = input.device_id
| and device_temperature.ts < input.ts
|when matched and input.operation = 'upsert' then update set *
|when matched and input.operation = 'delete' then delete
|when not matched then insert *
|""".stripMargin
)
はい、ここが update, insert, delete の最もキモとなるところ。
個人的には merge into という SQL 構文は知らなかったのだが、どうやら Iceberg 特有のものでもないらしい。
table device_temperature に対して update, delete, insert を行う SQL となっている。
このクエリが実行されると Iceberg の table が更新され、snapshot が1つ前に進むことになる。
DDL のところで merge-on-read を指定したため、差分のみのファイルが作成される。
table 更新の確認
上記のコードを実行すると、table の更新処理が始まる。
しばらく流した後、SparkSQL で
spark
.sql(
"""select
| *
|from
| my_catalog.my_db.device_temperature
|order by
| device_id
|""".stripMargin
)
.show(128, truncate = false)
のようなクエリを実行すると、
+---------+---------+------------------+-----------------------+
|device_id|operation|temperature |ts |
+---------+---------+------------------+-----------------------+
|0 |upsert |15.879340359832794|2023-05-08 07:39:56.637|
|1 |upsert |20.303530210621492|2023-05-08 07:40:26.157|
|2 |upsert |21.07822922592327 |2023-05-08 07:41:10.937|
|3 |upsert |20.81228214216027 |2023-05-08 07:37:09.756|
|6 |upsert |20.571664434275807|2023-05-08 07:38:43.124|
|7 |upsert |19.44731196983606 |2023-05-08 07:39:56.1 |
|8 |upsert |27.964942467735458|2023-05-08 07:39:39.623|
|9 |upsert |23.319385015293673|2023-05-08 07:40:59.377|
|10 |upsert |22.392313247902365|2023-05-08 07:40:40.946|
...
のような結果が得られる。
少し間をおいて実行すると中身が変わっており、更新されていることがわかる。
また、ある程度時間を経た後においても欠番があり (ex. 上記の device_id = 4, 5)、削除も行われていることが確認できる。
雑感
Apache Hudi に比べて動作が素直でわかりやすいように感じた。
一方で Hudi で言うところの PRECOMBINE_FIELD のようなものがなく、自分で重複排除する必要がありちょっと面倒。
必然的にタイムトラベルできる粒度は mini batch の粒度となる。
merge-on-read の table では差分ファイルが大きくなるにつれ、読み取りのコストも大きくなっていく。
上記の更新コードを一晩実行した後だと、単純な select に6分程度かかってしまった。
最新 snapshot としてはレコード数はたかだか128程度なのでこれはかなり遅い。
というところで compaction などの table のメンテナンス操作が必要となってくる。
これについては次のポストで扱いたい。