
最近よく聞かれるようになった「データレイク」という概念にあまりついていけていなかったため、いまさらながらざっと調べてみた。
データレイクとは
Wikipedia によると最初にこの言葉を使ったのは Pentaho 社の CTO である James Dixon らしい。
その時の彼のブログ (10年前…) を読むと、既にあったデータマートに対して
- Only a subset of the attributes are examined, so only pre-determined questions can be answered.
- The data is aggregated so visibility into the lowest levels is lost
–Pentaho, Hadoop, and Data Lakes - James Dixon’s Blog
というような問題意識からデータレイクというコンセプトを提案したようだ。
最近?のデータレイクについてはベンダー等の記事が参考になる。
書籍だと『AWSではじめるデータレイク: クラウドによる統合型データリポジトリ構築入門』がいいだろうか。
データレイクの概要と AWS が考えている構築・運用がざっとわかる。
Amazon で検索した限りだと現時点でタイトルに「データレイク」を含む和書はこれのみだった。

上に挙げたような文献ではデータレイクはデータウェアハウスとの対比という形でよく語られている。
共通している内容は概ね以下のとおり。
- 加工前データや非構造化データを含むあらゆるデータを保存
- データウェアハウスでは加工され構造化されたデータのみを含む
- データレイクでは加工前の半構造化、非構造化データも含む
- ex. ログ、画像、音声
- Scheme on Read
- 書き込み時にデータの構造を決める (Scheme on Write) のではなく、使用時に決める
- なので詳細なスキーマ設計なしに様々なデータを置いていくことができる
- 一元的なデータ管理
- データがサイロ化しないよう、組織全体のデータを一元的に管理
- なのでデータへのアクセス権の管理が重要になる
- 多様な分析用途に対応
- データウェアハウスはビジネスアナリストが決まったレポートを出すために使われる
- データレイクでは機械学習など更に高度な分析をデータサイエンティストが行う
機械学習の普及がデータレイクを強く後押ししているように思う。
機械学習をやっていれば様々な特徴量を扱いたいというのは自然な欲求であり、データレイクはそれを実現する。
また、クラウドベンダーは以下のような点も強調している。
- 従量課金のクラウドストレージによるメリット
- 運用開始前の時点でどんな生データがどれだけ来るか、見積もるのはとても難しい
- 従量課金のクラウドストレージ (Amazon S3, Google Cloud Storage, etc.) なら必要なときに必要なサイズだけ追加できる
- 安価なクラウドストレージの普及がデータレイクを後押し
- ストレージとコンピューティングの分離
- 処理側のリソースを処理内容に応じて確保できる
- 処理側のバージョンアップや変更が容易
- (オンプレ Hadoop クラスタのバージョンアップの辛さを思い出してください)
なるほどです。
沼にはまらないために
データレイクとの対比でデータスワンプ (沼) という言葉がある。
以下の説明がわかりやすいだろうか。
データスワンプ(Data Swamp)とは、データの沼地(Swamp)という意味です。これの対比語としてデータレイク(Data Lake:データの湖)があります。沼には、いろんな魚が住んでいるかもしれませんが、水が濁っているため、どこにどんな魚がいるか全く見えません。また、全く見えないため「魚が住んでいないんじゃないか」とも思い、魚を捕るのも諦めてしまいがちです。その一方で、湖は、水が澄んでいるため、魚を見ることができ「おっ!魚がいるな。何とか捕まえてみよう」と思えます。
この沼と湖にいる魚を、データの例えとして使っているのが、データスワンプと、データレイクという言葉です。
– データスワンプ - Realize
データスワンプにならないようにということについては次の資料が参考になる。
- The difference between a data swamp and a data lake? 5 signs
- Metadata Separates Data Lakes From Data Swamps
- From Data-Swamp to Data-Lake on AWS (Part 1)
すごくざっくりまとめるとデータレイクの構築・運用に当たって次の点に配慮するとよい。
- メタデータ、カタログの整備
- どんなに優れたデータレイクを構築したとしても、利用者がどこに何のデータがあるかわからないと意味がない
- 多種のデータ資産を一元的に管理するデータレイクにおいて目的のデータを見つけるために必要な機能
- データガバナンス
- 誰がどのデータに対して何ができるのか
- 統制をきつくしすぎると自由度が減るため、これらのバランスを考慮しないといけない
- その他、常識的な運用
クラウドベンダーが推進するデータレイク
クラウドベンダーがどのようなデータレイクを考えているかというのも見ておく。
GCP

Google Cloud データレイクとしての Cloud Storage
データレイクとしての Cloud Storage というドキュメントに GCP が考えるデータレイクの構成が記載されている。
構成としては以下のとおり。
- 保存: Cloud Storage
- 変換: Cloud Dataproc, Cloud Dataprep, Cloud Dataflow
- 分析: BigQuery, Cloud ML Engine, Cloud Datalab, etc.
データ保存のストレージとして、みんな大好きな BigQuery ではなく Cloud Storage を想定しているのは非構造化データを扱うためだろう。
いわゆるリレーショナル的なものより Cloud Storage や S3 のようなオブジェクトストレージの方がこの要件に適している。
もちろん Cloud Storage に保存された生データを処理してから BigQuery のデータウェアハウスに再びつっこむのも悪くない。
変換や分析には様々なサービスが使えるし、今後も幅は広がっていくと考えられる。
クラウドにおけるストレージとコンピューティングの分離の恩恵と言えるだろう。
現時点ではこのドキュメントにはカタログ化についての記述はないが、GCP には Data Catalog というサービスがあり Cloud Storage のメタデータを扱えるようだ。
AWS
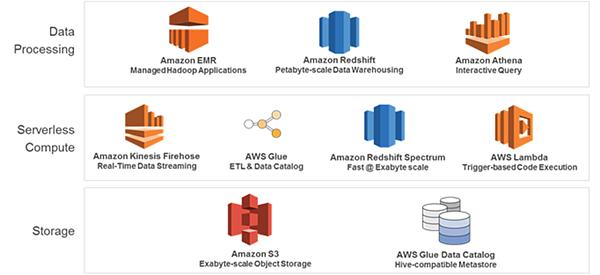
前述の書籍『AWSではじめるデータレイク: クラウドによる統合型データリポジトリ構築入門』に加え、Building Big Data Storage Solutions (Data Lakes) for Maximum Flexibility も読んでおくとよい。
- 保存: Amazon S3 (, AWS Glue Data Catalog)
- 変換: AWS Glue ETL, Amazon EMR, AWS Lambda, etc.
- 分析: Amazon Athena, Amazon Redshift Spectrum, Amazon ML, etc.
やはり中心となるのは S3 だ。
GCP も AWS もストレージのコストメリットを推している。
Glue Data Catalog がメタデータを管理する。
GCP 同様、変換・分析には様々なオプションがある。
Building Big Data Storage Solutions (Data Lakes) for Maximum Flexibility には記載がないのだが、AWS Lake Formation というサービスもある。
上に挙げたようなサービスの上に一枚被せて、データレイクとして運用しやすくするといったようなものらしい。
特に権限管理的な意味合いが強いように思う。
組織のデータを一元的に管理するデータレイクには様々な部署・役割の人からのアクセスがある。
どのデータを誰が扱えるのか、複数のサービスを横断して IAM で権限を管理のはかなりきつそうな印象でそういうのを楽にしてくれるのだろう。
まとめ
データレイクの概観やベンダーが考えていることがわかった。
普段業務で使っているということもあり、全体的に AWS 寄りになってしまったように思うのでその点をご留意していただきたい。
この後はデータレイク関連の OSS について調べておきたいところ。